

Comprendre Random Forest : Une méthode d'ensemble
Le modèle de forêt aléatoire (RF), proposé pour la première fois par Tin Kam Ho en 1995, est une sous-classe des méthodes d'apprentissage ensembliste qui s'applique à la classification et à la régression. Une méthode d'ensemble construit un ensemble de classificateurs - un groupe d'arbres de décision, dans le cas du modèle RF - et détermine l'étiquette de chaque instance de données en prenant la moyenne pondérée des résultats de chaque classificateur.
L'algorithme d'apprentissage utilise l'approche "diviser pour régner" et réduit la variance inhérente à une instance unique du modèle par le biais de l'amorçage. Par conséquent, "l'assemblage" d'un groupe de classificateurs plus faibles augmente les performances et le classificateur agrégé qui en résulte est un modèle plus fort.
La forêt décisionnelle aléatoire est une modification du bagging - agrégation bootstrap, proposée par Leo Breiman en 2001 - qui assemble une grande collection d'arbres décorrélés sur des caractéristiques sélectionnées de manière aléatoire[1]. Le "nombre d'arbres" composant la forêt est lié à la variance du modèle, tandis que la "profondeur de l'arbre" ou le "nombre maximum de nœuds composant chaque arbre" est associé au biais irréductible présent dans le modèle.

La RF présente un certain nombre d'avantages : Elle est très rapide à mettre en œuvre et à exécuter (elle fonctionne efficacement sur de grands ensembles de données), elle est l'un des algorithmes d'apprentissage les plus précis et elle est résistante à l'ajustement excessif et aux valeurs aberrantes[2]. Les performances de RF sont similaires, mais plus robustes, que celles des arbres de décision boostés par le gradient (GBDT), une autre sous-classe de méthodes d'ensemble d'arbres. En outre, étant donné que la méthode RF comporte moins d'hyperparamètres que la méthode GBDT, elle est plus facile à entraîner et à régler. Par conséquent, la RF est très populaire et est prise en charge dans divers langages tels que R et SAS, ainsi que dans de nombreux paquets en Python, notamment scikit-learn et TensorFlow.
Estimateur TensorForest : Compatibilité et utilisation
TensorFlow a récemment inclus le support de RF dans la base de code contributif - tf.contrib - à travers un module nommé tensor_forest (défini dans https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/tensor_forest/__init__.py, notez que le lien vers tensor_forest sur le site officiel de TensorFlow dirige l'utilisateur vers la branche avec la version la plus récente et non pas vers la branche principale). La version 1.3.0 de tensor_forest a subi des modifications importantes par rapport à la version 1.2.0 et la structure du code et les paramètres à discuter sont conformes à la version 1.2.0.
Structure et mise en œuvre de TensorForest
Les modules suivants doivent être importés pour utiliser tensor_forest :
- from tensorflow.contrib.learn.python.learn import metric_spec
- from tensorflow.contrib.learn.python.learn.estimators import estimator
- from tensorflow.contrib.tensor_forest.client import eval_metrics
- from tensorflow.contrib.tensor_forest.client import random_forest
- from tensorflow.contrib.tensor_forest.python import tensor_forest
L'étape initiale de l'exécution de RF dans TensorFlow est la construction du modèle. Pour construire un estimateur RF, il faut d'abord spécifier les hyperparamètres du RF comme suit :
hparams = tensor_forest.ForestHParams(num_classes=NUM_CLASSES,num_features=NUM_FEATURES,num_trees=NUM_TREES,max_nodes=MAX_NODES,min_split_samples=MIN_NODE_SIZE).fill()Chacun des hyperparamètres de la forêt tensorielle mentionnés ci-dessus est décrit ci-dessous :
``num_classes`` : Le nombre de classes possibles pour les étiquettes
``num_features`` : Le nombre de caractéristiques. Soit `num_splits_to_consider` soit `num_features` devrait
Selon les contributeurs au code de tensor_forest, le modèle est plus précis.
when ``num_splits_to_consider`` == ``num_features``[4].
``num_trees`` : Le nombre d'arbres à construire pour prendre le mode [pour la classification] ou la moyenne [pour la classification].
régression] des prédictions. Les arbres sont "notoirement bruyants" et "bénéficient donc grandement de l'établissement d'une moyenne"[5]. Plus il y a d'arbres dans la forêt, plus la variance du modèle est faible et plus les résultats sont précis. Cependant, il existe un compromis entre la performance des résultats et la vitesse d'exécution. L'utilisation d'un grand nombre d'arbres entraîne un coût de calcul plus élevé et peut ralentir considérablement le code. En général, après un certain nombre d'arbres, les performances du modèle plafonnent et l'amélioration est négligeable[6].
J'aime construire une forêt de cinq arbres pour tester mon code à des fins de débogage, une forêt de 100 arbres pour avoir une première idée de l'exactitude, de la précision, du rappel, de l'auc, etc. et une forêt de 500 arbres pour un modèle final qui ne nécessite pas d'ajustements majeurs. En général, l'utilisation d'un modèle de 1000 arbres n'augmente pas significativement les performances par rapport à une forêt de 500 arbres.
*Par défaut : 100
Les deux hyperparamètres suivants déterminent la profondeur des arbres dans une forêt. Limiter la profondeur des arbres n'apporte aucun avantage supplémentaire autre que la limitation du temps de calcul et n'est pas recommandé[7]. Une profondeur plus importante signifie un biais plus faible. Lorsque les arbres "poussent suffisamment profondément, [ils] ont un biais relativement faible"[8].
``max_nodes`` : Le nombre maximum de noeuds autorisé pour chaque arbre. Un nombre plus élevé de ``max_nodes``
permet d'avoir des arbres plus profonds.
*Par défaut : 10000.
``min_split_samples`` : "Le nombre minimum d'échantillons requis pour diviser un nœud interne" selon
SKlearn[9]. ``min_split_samples`` est lié à la taille minimale des nœuds. Plus le nombre d'échantillons requis pour diviser un nœud est faible, plus l'arbre peut devenir profond.
*Par défaut : 5

Ensuite, déterminez le type de graphe à utiliser avec RF ; il y a deux types de graphes : Le graphe RF par défaut [``RandomForestGraphs``] et le graphe de perte d'entraînement [``TrainingLossForest``][11]. Pour l'a priori, l'utilisateur peut pondérer les instances positives, généralement pour les ensembles de données déséquilibrés, en passant un vecteur de poids.
[Note : ``SKCompat`` est le wrapper scikit-learn pour TensorFlow[12]. ``model_dir`` doit être un répertoire où sont sauvegardés le RF et le fichier de log pour la visualisation tensorboard].
Si le graphique RF est sélectionné :
Pour spécifier un surpoids :
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator(
params,
graph_builder_class=graph_builder_class,
model_dir=MODEL_DIRECTORY,
nom_du_poids='poids'))
Ou conserver la pondération par défaut de 1:1 entre les points de données positifs et négatifs :
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator(
params,
graph_builder_class=graph_builder_class,
model_dir=MODEL_DIRECTORY))
Dans le cas de la forêt de perte d'entraînement, la perte d'entraînement calculée à partir de la fonction de perte par défaut [``log_loss``] ou d'une fonction de perte spécifiée est utilisée pour ajuster les poids[13].
Utiliser la fonction de perte par défaut ``log loss`` :
graph_builder_class = tensor_forest.TrainingLossForest
Ou spécifier une fonction de perte à utiliser dans le graphique de perte d'apprentissage[14] :
from tensorflow.contrib.losses.python.losses import loss_ops
# Les fonctions de perte valides sont les suivantes
#["absolute_difference",
#"add_loss",
#"cosine_distance",
#"compute_weighted_loss",
#"get_losses",
#"get_regularization_losses",
#"get_total_loss",
#"hinge_loss",
#"log_loss",
#"mean_pairwise_squared_error",
#"mean_squared_error",
#"sigmoïde_cross_entropy",
#"softmax_cross_entropy",
#"sparse_softmax_cross_entropy"]
def loss_fn(val, pred) :
_loss = loss_ops.hinge_lss(val, pred)
retour _perte
def _build_graph(params, **kwargs) :
return tensor_forest.TrainingLossForest(params,
loss_fn=_loss_fn, **kwargs)
graph_builder_class = _build_graph
Enfin, construisez l'estimateur RF avec les hyperparamètres et le graphique spécifiés précédemment. est= estimator.SKCompat(random_forest.TensorForestEstimator(
hparams,
graph_builder_class=graph_builder_class,
model_dir=MODEL_DIRECTORY))
Une fois le RF construit, ajustez le modèle aux données d'entraînement via la méthode ``fit``.
Pour le graphique RF avec le surpoids spécifié* :
est.fit(x={‘x’:x_train, ‘weights’:train_weights},
y={‘y’:y_train},
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS)
*Note : `weights` doit être la même clé que celle passée dans ``TensorForestEstimator`` plus tôt.
``train_weights`` doit être de dimension : (nombre d'échantillons, )
Pour la pondération par défaut 1:1 ou la forêt de perte de formation :
est.fit(x=x_train, y=y_train
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS)
Pour évaluer les résultats produits par le modèle, identifiez les métriques souhaitées et transmettez-les à la fonction ``evaluate``[15].
# Les autres indicateurs sont les suivants
# true positives : tf.contrib.metrics.streaming_true_positives
# true negatives : tf.contrib.metrics.streaming_true_negatives
# faux positifs : tf.contrib.metrics.streaming_false_positives
# faux négatifs : tf.contrib.metrics.streaming_false_negatives
# auc : tf.contrib.metrics.streaming_auc
# r2 : eval_metrics.get_metric('r2')
# précision : eval_metrics.get_metric('precision')
# recall : eval_metrics.get_metric('recall')
metric = {‘accuracy’:metric_spec.MetricSpec(eval_metris.get_metric(‘accuracy’),
prediction_key=eval_metrics.get_prediction_key('accuracy')}
En cas de surcharge pondérale :
model_stats = est.score(x={‘x’:x_test, ‘weights’:test_weights},
y={‘y’:y_test},
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS,
metrics=metric)
pour metric dans model_stats :
print('%s : %s' % (metric, model_stats[metric])
Pour la pondération par défaut et la forêt de perte de formation :
model_stats = est.score(x=x_test, y=y_test)
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS,
metrics=metric)
pour metric dans model_stats :
print('%s : %0.4f' % (metric, model_stats[metric])
Pour l'étiquette prédite et la probabilité de chaque classe pour chaque instance de données :
[Note : ``predicted_prob`` et ``predicted_class`` sont des tableaux numpy qui préservent l'ordre de l'entrée originale.]
Le surpoids est spécifié :
predictions = dict(est.predict({‘x’:x_test, ‘weights’:test_weights}))
predicted_prob = predictions[eval_metrics.INFERENCE_PROB_NAME]
predicted_class = predictions[eval_metrics.INFERENCE_PRED_NAME]
Pondération par défaut et forêt de perte de formation :
predictions = dict(est.predict(x=x_test))
predicted_prob = predictions[eval_metrics.INFERENCE_PROB_NAME]
predicted_class = predictions[eval_metrics.INFERENCE_PRED_NAME]
Enfin, lancez tensorboard via le terminal pour visualiser le processus d'apprentissage et le graphe TensorFlow :
Le répertoire précédemment passé à ``model_dir`` doit être fourni.
$ tensorboard --logdir="./"
Ouvrez http://localhost:6006/ ou le lien obtenu en exécutant la commande ci-dessus dans le navigateur pour afficher tensorboard.

Comparaison entre TensorFlow et Scikit-Learn pour les modèles Random Forest
Actuellement, TensorFlow et scikit-learn sont tous deux des modules très populaires, chacun avec des équipes d'experts qui contribuent et maintiennent la base de code, une myriade de tutoriels sur l'utilisation du code en ligne et sur papier, la couverture de la plupart des algorithmes d'apprentissage automatique. Cependant, ces deux modules ne visent pas les mêmes tâches.
scikit-learn

Scikit est depuis longtemps considéré comme le "cadre officiel de facto de l'apprentissage automatique général en Python"[17]. Il offre une base de code complète d'algorithmes d'apprentissage automatique appartenant à diverses catégories : classification, régression, regroupement, réduction de la dimensionnalité, etc[18]. Ces algorithmes bien conçus offrent aux utilisateurs un accès standard à une analyse facile et rapide de l'ensemble des données. Par exemple, sklearn comprend un module RF qui peut être déployé sur des ensembles de données en quelques lignes seulement :

Outre sa facilité d'utilisation et son API standardisée, scikit-learn est également extraordinairement bien documenté. Pour chaque bibliothèque, des pages sont consacrées non seulement à la description de l'interface, des paramètres d'entrée et du format de sortie, mais aussi à la démonstration de l'utilisation du code à l'aide d'exemples soigneusement construits. Le module RF de sklearn sert à nouveau d'illustration spécifique :
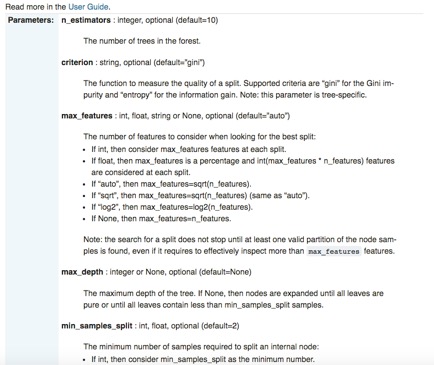

Bien que scikit-learn présente de nombreux avantages importants tels que la "brièveté syntaxique"[22], il présente une lacune particulière : sklearn ne prend pas en charge les GPU et ne le fera pas dans un avenir proche[23]. "La prise en charge des GPU introduira de nombreuses dépendances logicielles et des problèmes spécifiques à la plate-forme. [En dehors des réseaux neuronaux, les GPU ne jouent pas un rôle important dans l'apprentissage automatique aujourd'hui", selon le site officiel de sklearn. En revanche, la prise en charge native du GPU par TensorFlow est particulièrement adaptée à l'apprentissage profond.
TensorFlow
La puissance de TensorFlow réside dans son évolutivité pour "former des réseaux neuronaux profonds sur des GPU [et] éventuellement sur des grappes de plusieurs machines"[24], et dans la liberté accordée aux utilisateurs pour assembler leurs propres algorithmes d'apprentissage profond. Les utilisateurs spécifient non seulement le type de modèle utilisé, mais aussi la manière dont il est mis en œuvre en utilisant les primitives fournies par le cadre[25]. Ils définissent exactement "comment [...] les données doivent être transformées [et] quelle fonction de perte le modèle doit optimiser"[26]. En outre, TensorFlow est très flexible et portable ; il est disponible sur de nombreuses plateformes - notamment Ubuntu, Mac OS X, Windows, Android, iOS - et une variété de langages, tels que Python, Java, C, Go[27]. Bien qu'il semble particulièrement attrayant en raison de son évolutivité et de son intégrabilité, la structure de code compliquée de TensorFlow, ses messages d'erreur mystérieux et, dans certains cas, ses modules mal documentés surchargent le processus de débogage. Par conséquent, l'utilisation de TensorFlow pour "la plupart des tâches pratiques d'apprentissage automatique" est probablement exagérée[28].
Présentation de Scikit Flow : un pont entre TensorFlow et Scikit-Learn
[https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/learn/python/learn]
Scikit flow (SKFlow) est présenté comme une solution au dilemme scikit-TensorFlow : il exploite la "puissance de modélisation de TensorFlow en canalisant la brièveté syntaxique de scikit-learn"[29]. SKFlow est un projet officiel développé par Google qui fournit une enveloppe simplifiée de haut niveau pour TensorFlow[30].
Un réseau neuronal à trois couches avec respectivement 10, 20 et 10 unités cachées peut être mis en œuvre avec quatre lignes dans SKFlow :

Ou construire un modèle personnalisé avec SKFlow avec environ 10 lignes de code :
