

Toute organisation détenant des données sensibles peut être la cible d'une cyberattaque, quelle que soit sa taille ou son secteur d'activité. Alors que de plus en plus d'entreprises se tournent vers le site cloud, le paysage des menaces évolue à un rythme accéléré et les adversaires déploient des tactiques avancées pour atteindre leur objectif. La réponse aux incidents joue un rôle essentiel dans la sécurisation de vos données et la prévention d'une attaque qui ferait des ravages dans votre organisation.
La base d'un programme réussi de réponse aux incidentscloud se concentre sur la préparation, les opérations et l'activité post-incident. Le NIST et le SANS , deux organisations de confiance, ont développé des cadres de RI avec des étapes de réponse aux incidents qui s'alignent étroitement sur ces phases. Vectra AI CDR for AWS Incident Response a été développé sur la base de ces phases, par nécessité de s'aligner sur le cycle de vie de la réponse aux incidents du NIST, couplé à des opérations englobant la détection, l'analyse avec confinement, l'éradication et la récupération pilotées par l'IA. Le guide AWS Security Incident Response présente de nombreuses méthodes d'automatisation des techniques de réponse aux incidents.
Le guide AWS Security Incident Response souligne qu'il est essentiel de se préparer à un incident. Après avoir détecté un événement lors de la phase de détection d'une réponse à un incident et l'avoir analysé lors de la phase d'analyse, vous pouvez utiliser la solution automatisée pour contenir les quatre services AWS pris en charge. Le confinement de l'incident est essentiel pour traiter les menaces en temps réel. À quoi ressemble une instance de confinement automatisée ?
Pourquoi Vectra's AWS entity lockdown
La sécurité est la priorité absolue de Vectra. AWS a un modèle de responsabilité partagée : AWS gère la sécurité du site cloud, et les clients sont responsables de la sécurité du site cloud. Un tel modèle laisse au client le contrôle total de sa mise en œuvre de la sécurité, mais la réponse aux incidents de sécurité peut s'avérer complexe. L'adoption des fonctionnalités d'automatisation du verrouillage des entités de Vectra CDR for AWS améliore la vitesse de réaction de vos équipes SecOps et simplifie les opérations de réponse aux incidents, de sorte que votre organisation est mieux préparée en cas d'événement et peut minimiser la menace avant qu'elle ne fasse des ravages au sein de votre organisation.
Voici comment nous procédons :
SecOps doit réagir et enquêter lorsqu'un écart par rapport à la ligne de base se produit, par exemple à la suite d'une mauvaise configuration ou d'un changement de facteurs externes. Vectra La solution CDR for AWS Entity Lockdown prépare mieux votre équipe aux événements de sécurité en fournissant les éléments suivants :
- Principe AWS du moindre privilège: Il suffit d'exposer une autorisation de publication SNS. Accès fortement contrôlé.
- Flux de travail automatisé: La solution peut s'intégrer parfaitement dans les flux de travail existants et être activée automatiquement pour assurer un contrôle hors bande afin d'empêcher les attaques de s'intensifier et d'avoir un impact.
- Piste d'audit automatisée : La solution permet d'effectuer des audits de conformité et d'enregistrer les données.
- Interrégionale et inter-comptes: Travaillez à partir d'un seul endroit dans l'ensemble de votre environnement AWS pour simplifier l'utilisation.
- Spécifique/ciblée: Assure que les informations d'identification compromises sont entièrement verrouillées, de sorte que l'attaquant ne puisse pas simplement utiliser un chemin d'attaque différent. Cela permet de s'assurer que seules les informations d'identification compromises sont verrouillées afin d'éviter tout impact sur les activités habituelles.
Architecture et conception du confinement AWS
Vectra CDR pour AWS utilise un message de sujet AWS SNS pour déclencher une fonction Lambda. Tout d'abord, le message AWS SNS est publié soit manuellement, soit par l'intermédiaire d'un outil tiers, par exemple Amazon Security Hub ou SOAR. Ensuite, le code Lambda déclenche d'autres actions en fonction du contenu du message. Le message SNS nécessite deux attributs de message. Un ARN de l'entité à isoler et un ExtranalId. L'utilisateur définit l'ExtranalId lors du déploiement du modèle CloudFormation. Ce champ est statique et est utilisé pour valider le message SNS par la fonction Lambda de réponse aux incidents.
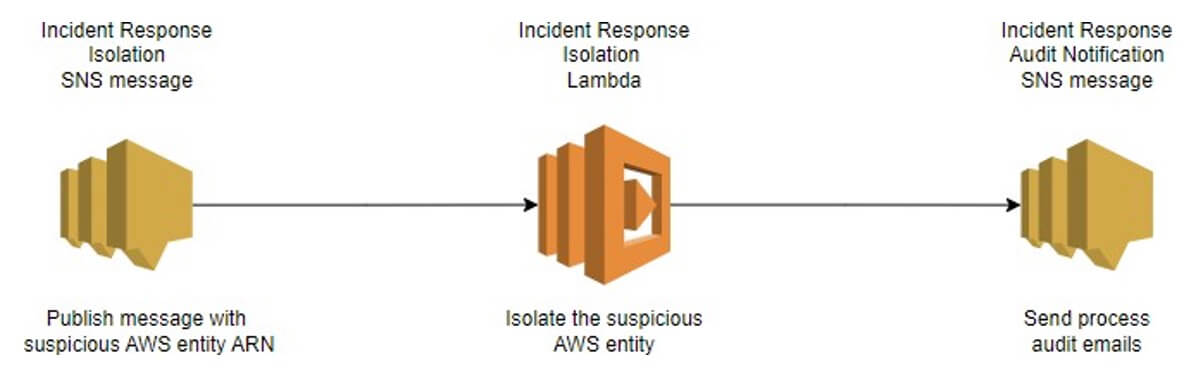
Cela permettra d'accomplir les tâches suivantes, comme l'illustre la figure 1 :
- Un message AWS SNS est publié avec un ARN d'entité AWS pour le confinement et l'ExternalId.
- Une fonction AWS Lambda est invoquée par le message SNS. La fonction Lambda exécute la logique métier de la réponse à l'incident en fonction du type d'entité.
- Un courriel d'audit AWS SNS sera envoyé à l'utilisateur tout au long du processus. Un courriel au début du processus, un autre en cas de succès ou d'échec, et un autre si le message tombe dans la file d'attente des lettres mortes.
Lorsque la fonction Lambda est invoquée, la logique métier suivante est exécutée : La logique métier de la réponse aux incidents est illustrée à la figure 2.
Déterminer le type d'entité AWS. Entités prises en charge : Lambda, Utilisateur IAM, Rôle IAM et EC2.
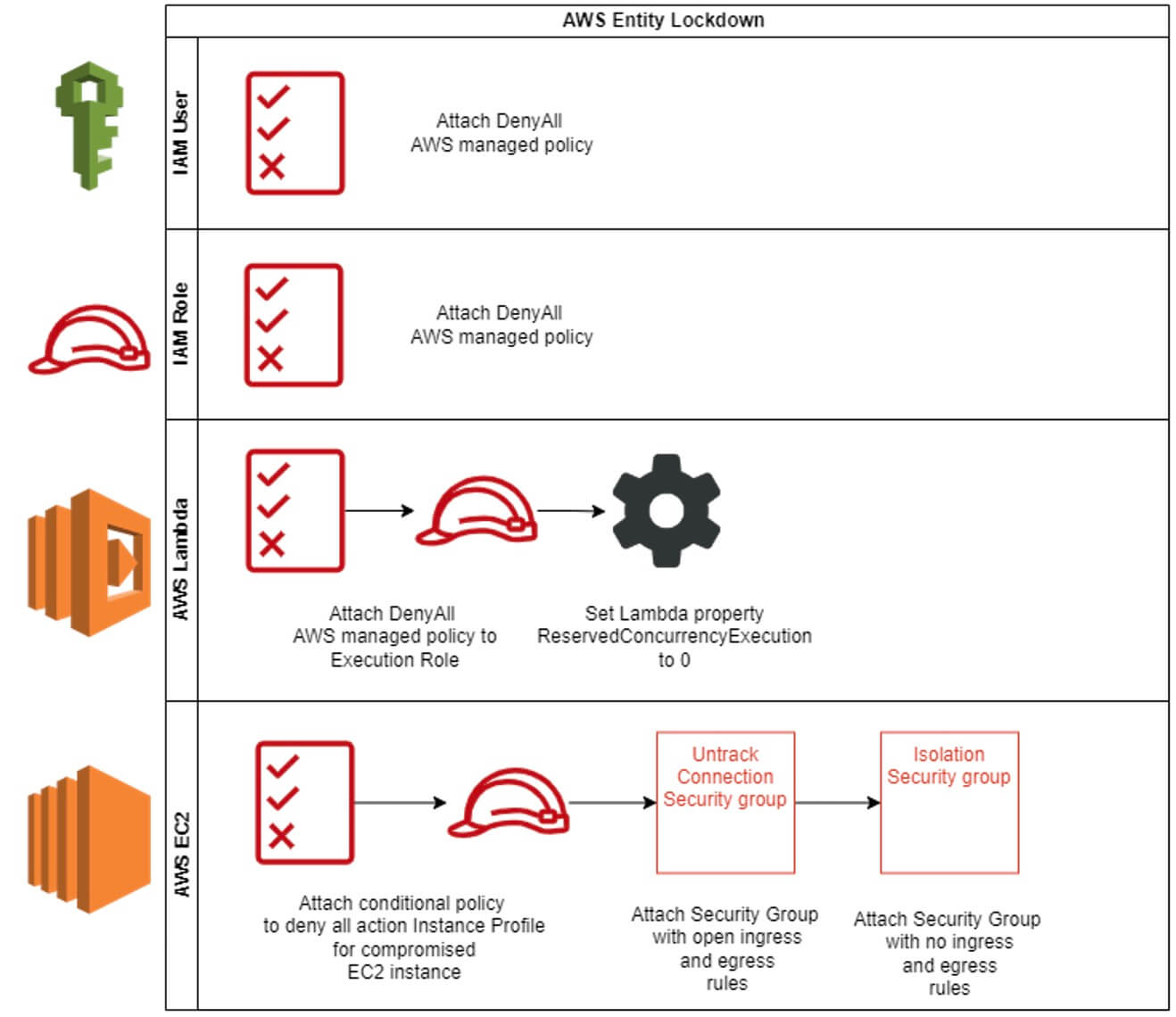
La fonctionLambda attachera une politique gérée par AWS DenyAll si le type d'entité est IAM Role ou User.

Si le type d'entité est une fonction AWS Lambda, la logique suivante est appliquée :
- Attachez la politique gérée AWS DenyAll au rôle d'exécution Lambda.
- Définissez la propriété de la fonction Lambda function_currency à 0, ce qui empêchera le déclenchement de la fonction.

La logique suivante est appliquée si le type d'entité est une instance AWS EC2.

Les règles des groupes de sécurité commencent par un refus implicite de tout trafic. En l'absence de règles, vous créez des règles autorisant un trafic spécifique. Le trafic entrant est autorisé sans tenir compte des règles de sortie et vice versa ; c'est ainsi qu'AWS implémente les connexions avec état au sein des groupes de sécurité. Vous pouvez ajouter ou supprimer des règles à tout moment, et les modifications sont immédiatement appliquées aux instances associées au groupe de sécurité. Cependant, l'effet de certaines modifications de règles peut dépendre de la manière dont le trafic est suivi. Il est essentiel de comprendre le fonctionnement des connexions suivies pour mettre en œuvre un confinement efficace des groupes de sécurité. Si une connexion est suivie, elle peut maintenir la connectivité internet, même si elle est rattachée à un groupe de sécurité sans règles. Les groupes de sécurité utilisent le suivi des connexions pour suivre les informations sur le trafic en provenance et à destination de l'instance - c'est ainsi qu'ils mettent en œuvre des connexions actives, même si tous les flux de trafic ne sont pas suivis. Il y a une exception... Le trafic ICMP est toujours suivi.
Les connexions non suivies s'appliquent à tout type de trafic avec une règle quadruple zéro pour tous les ports dans les deux sens. Vous pouvez voir des exemples de connexions suivies et non suivies.
- TCP ou UDP pour tout le trafic (0.0.0.0/0 Tracked. :/0) et qu'il existe une règle correspondante dans l'autre direction qui autorise tout le trafic de réponse (0.0.0.0/0 ou :/0) pour tous les ports (0-65535), alors ce flux de trafic n'est pas suivi - Not tracked (non suivi).
- Le trafic TCP entrant et sortant sur le port 22 (SSH) est suivi, car la règle d'entrée n'autorise que le trafic provenant de 203.0.113.1/32, et non de toutes les adresses IP (0.0.0.0/0) - Suivi.
- Le trafic TCP entrant et sortant sur le port 80 (HTTP) n'est pas suivi, car les règles d'entrée et de sortie autorisent le trafic en provenance de toutes les adresses IP - Non suivi.
- Le trafic ICMP est toujours suivi - Suivi.
Si vous supprimez la règle de sortie pour le trafic IPv4, tout le trafic IPv4 entrant et sortant est suivi, y compris le trafic sur le port 80 (HTTP). Il en va de même pour le trafic IPv6 si vous supprimez la règle de sortie pour le trafic IPv6. - Suivi.
Les groupes de sécurité sont très efficaces et ciblent le confinement d'une seule instance Ec2. L'arrêt des connexions suivies et non suivies nécessite un processus en plusieurs étapes pour mettre fin aux connexions actives et empêcher toute nouvelle connexion. Toutes les connexions non suivies sont immédiatement interrompues lors de l'application de la solution de verrouillage de l'entité Vectra . Toutefois, seules les connexions actives suivies sont interrompues, ce qu'il est très important de comprendre. Dans notre solution, les connexions actives sont toutes les connexions dont le trafic réseau est continu ou ne dépasse pas une minute d'intervalle.

La solution suivante fonctionne pour les connexions actives en continu. Par exemple, si l'instance EC2 compromise est utilisée pour le minage de crypto-monnaie ou fait partie d'une attaque de ransomware.
Lorsque la fonction Lambda de réponse aux incidents est invoquée et que le type d'entité à isoler est une instance AWS EC2, les actions suivantes sont effectuées.
- Attacher une politique conditionnelle pour refuser toute action au profil d'instance pour l'instance EC2 compromise. De nombreuses solutions suggèrent de détacher le rôle du profil d'instance de l'instance. Cependant, bien qu'une telle action empêche l'instance d'initier de nouvelles sessions, elle ne révoque pas les sessions existantes. Par exemple, si l'attaquant a exploité une application mal configurée et a obtenu des identifiants de sécurité à partir des métadonnées de l'instance, ces identifiants resteront actifs jusqu'à 12 heures.
- Vérifie dans le VPC où résident les instances EC2 s'il existe un groupe de sécurité pour les connexions non suivies ; si ce n'est pas le cas, il faut en créer un, puis appliquer le groupe de sécurité à l'instance. Ce groupe de sécurité a une seule règle d'entrée et de sortie de 0.0.0.0/0, convertissant les connexions suivies en connexions non suivies.
- Vérifiez l'existence d'un groupe de sécurité d'isolation dans le VPC. S'il n'en existe pas, créez-en un, puis appliquez le groupe de sécurité à l'instance. Ce groupe de sécurité n'a pas de règles d'entrée et de sortie. L'attribution de ce groupe de sécurité isolera complètement l'instance EC2.

Déploiement de Vectra CDR pour AWS
Pour déployer Vectra CDR pour AWS, vous devez d'abord accéder aux modèles CloudFormation. Si vous utilisez un seul compte AWS, vous n'aurez besoin que du modèle de déploiement des ressources de réponse aux incidents. Cependant, vous devrez déployer deux modèles si vous avez une configuration multi-comptes et que vous souhaitez une solution de réponse aux incidents inter-comptes. Le déploiement du premier modèle dans votre compte de sécurité AWS hébergera les ressources de réponse aux incidents. Le second modèle créera un rôle IAM inter-comptes dans les autres comptes que vous souhaitez voir couverts par la solution. Le README de la solution documente entièrement les modèles AWS CloudFormation et les détails de la pile. Vous pouvez trouver des ressources supplémentaires dans le dépôt GitHub.
Vectra CDR pour AWS Automation
Pour commencer votre automatisation, vous devrez d'abord déployer Vectra CDR pour la pile AWS CloudFormation. Ensuite, si vous utilisez la console AWS, vous pouvez publier un message SNS à partir de l'écran des ressources de service. Si vous souhaitez utiliser le CLI AWS ou le SDK AWS, l'ARN SNS de la réponse aux incidents peut être trouvé dans l'onglet de sortie de la pile AWS CloudFormation. Une description détaillée de chaque approche peut être trouvée dans le README du dépôt GitHub.
Comment endiguer les incidents liés au SAP
Comme indiqué précédemment, en suivant le CloudFormation, votre analyste SOC n'aura besoin que des privilèges de publication SNS pour répondre à un incident AWS. Un service de sécurité tel qu'Amazon Security Hub ou SOAR peut également publier un message dans le cadre du flux de travail de l'équipe SecOps. Par conséquent, l'analyste SOC n'a pas besoin de privilèges administratifs sur les services AWS suspects. En suivant les étapes décrites, votre équipe SecOps sera en mesure de créer une réponse aux incidents en utilisant les outils AWS natifs. Cette méthodologie prend également en charge le confinement inter-comptes et inter-régions. Si vous supprimez la pile dans chaque compte, un nettoyage manuel sera nécessaire pour supprimer ces groupes de sécurité créés pour l'isolation EC2.
La réponse aux incidents fait partie intégrante d'une stratégie de cybersécurité pour toutes les entreprises. Grâce au confinement des incidents AWS, votre équipe SecOps aura l'assurance de savoir comment automatiser l'isolation d'une instance EC2, d'un utilisateur et d'un rôle IAM, et d'une fonction Lambda pour répondre à toute entité suspecte dans votre environnement AWS.
Quelle est la prochaine étape ?
Découvrez la puissance de Vectra CDR pour AWS grâce à notre essai gratuit.