

Définir l'intelligence artificielle (IA) est une tâche complexe, souvent sujette à des perspectives changeantes. Les définitions basées sur les objectifs ou les tâches peuvent changer au fur et à mesure que la technologie progresse. Par exemple, les systèmes de jeu d'échecs ont été au centre des premières recherches sur l'IA jusqu'à ce que Deep Blue d'IBM batte le grand maître Gary Kasparov en 1997, ce qui a modifié la perception des échecs, qui n'exigeaient plus d'intelligence, mais des techniques de force brute.
D'autre part, les définitions de l'IA qui tendent à se concentrer sur des motifs procéduraux ou structurels s'enlisent souvent dans des questions philosophiques fondamentalement insolubles sur l'esprit, l'émergence et la conscience. Ces définitions ne nous permettent pas de mieux comprendre comment construire des systèmes intelligents et ne nous aident pas à décrire les systèmes que nous avons déjà construits.
Le test de Turing - Une mesure de l'intelligence des machines

Le test de Turing, souvent considéré comme un test de l'intelligence des machines, était le moyen pour Alan Turing de contourner la question de l'intelligence. Il a mis en évidence le flou sémantique de l'intelligence et s'est concentré sur ce que les machines peuvent faire plutôt que sur la façon dont nous les étiquetons.
La question initiale "Les machines peuvent-elles penser ? me paraît trop vide de sens pour mériter d'être discutée. Néanmoins, je pense qu'à la fin du siècle, l'usage des mots et l'opinion générale des gens instruits auront tellement changé que l'on pourra parler de machines pensantes sans s'attendre à être contredit". - Alan Turing
En fin de compte, il s'agit d'une question de convention, qui n'est pas très différente du débat sur la question de savoir s'il faut appeler les sous-marins "nager" ou les avions "voler". Pour Turing, ce qui importe vraiment, ce sont les limites des capacités des machines, et non la manière dont nous les désignons.
Mesurer la pensée humaine dans l'IA
À cette fin, si vous voulez savoir si les machines peuvent penser comme les humains, votre meilleur espoir est de mesurer à quel point la machine peut tromper d'autres personnes en leur faisant croire qu'elle pense comme les humains. À l'instar de Turing et de la définition fournie par les organisateurs du premier atelier sur l'IA en 1956, nous estimons que "chaque aspect de l'apprentissage ou toute autre caractéristique de l'intelligence peut en principe être décrit avec une telle précision qu'une machine peut être amenée à le simuler".
Pour obtenir des performances ou un comportement semblables à ceux de l'homme dans une tâche donnée, l'IA doit être capable de les simuler avec un niveau de précision remarquable. Le célèbre test de Turing a été conçu pour évaluer cette capacité en mesurant l'efficacité avec laquelle un ordinateur ou une machine pouvait tromper un observateur au cours d'une conversation non structurée. Le test original de Turing demandait même à la machine de représenter de manière convaincante une identité féminine.
Évaluer la compréhension de l'IA au niveau humain
Ces dernières années, des avancées significatives dans les techniques d'apprentissage automatique, associées à l'abondance de données d'entraînement, ont permis aux algorithmes d'engager une conversation avec un minimum de compréhension. En outre, des tactiques apparemment insignifiantes, telles que l'incorporation délibérée de fautes d'orthographe et de grammaire aléatoires, contribuent à rendre les algorithmes de plus en plus persuasifs en tant qu'humains virtuels, bien qu'ils soient dépourvus d'une véritable intelligence.
De nouvelles approches pour évaluer la compréhension au niveau humain, telles que les schémas de Winograd, proposent d'interroger une machine sur sa connaissance du monde, de l'utilisation des objets et des possibilités qui sont communément comprises par les humains. Par exemple, si nous posions la question suivante : "Pourquoi le trophée ne rentre-t-il pas sur l'étagère ? Parce qu'il était trop grand. Qu'est-ce qui était trop grand ?", n'importe qui constaterait immédiatement que le trophée est l'élément surdimensionné. À l'inverse, en procédant à une simple substitution - "Le trophée ne tenait pas sur l'étagère parce qu'il était trop petit. Qu'est-ce qui était trop petit ?", nous nous interrogeons sur l'inadéquation de la taille.
Dans ce scénario, la réponse se trouve sans équivoque dans la tablette. Ce test, d'une précision accrue, plonge dans les profondeurs de la connaissance du monde par les machines. Une simple exploration de données ne suffit pas à fournir une réponse. Cette définition implique qu'une IA ait la capacité d'émuler n'importe quelle facette du comportement humain, ce qui établit une distinction significative avec les systèmes d'IA spécifiquement conçus pour faire preuve d'intelligence dans le cadre de tâches particulières.
Différencier les types d'IA et leurs méthodes d'apprentissage
Intelligence générale artificielle (AGI)
L'intelligence artificielle générale (AGI), communément appelée IA générale, est le concept le plus fréquemment abordé lorsqu'il est question d'IA. Elle englobe les systèmes qui évoquent des notions futuristes de "robots dominateurs" régnant sur le monde, et qui ont capté notre imagination collective à travers la littérature et le cinéma.
IA spécifique ou appliquée
La plupart des recherches dans ce domaine se concentrent sur des systèmes d'IA spécifiques ou appliqués. Ceux-ci englobent un large éventail d'applications, depuis les systèmes de reconnaissance vocale et de vision par ordinateur de Google et Facebook jusqu'à l'IA de cybersécurité mise au point par notre équipe à l'adresse Vectra AI.
Les systèmes appliqués utilisent généralement une gamme variée d'algorithmes. La plupart des algorithmes sont conçus pour apprendre et évoluer au fil du temps, en optimisant leurs performances au fur et à mesure qu'ils ont accès à de nouvelles données. La capacité à s'adapter et à apprendre en réponse à de nouvelles données définit le domaine de l'apprentissage automatique. Toutefois, il est important de noter que tous les systèmes d'IA n'ont pas besoin de cette capacité. Certains systèmes d'IA peuvent fonctionner à l'aide d'algorithmes qui ne reposent pas sur l'apprentissage, comme la stratégie de Deep Blue pour jouer aux échecs.
Toutefois, ces occurrences sont généralement confinées à des environnements et des espaces de problèmes bien définis. En effet, les systèmes experts, un pilier de l'IA classique (GOFAI), s'appuient largement sur des connaissances préprogrammées et basées sur des règles plutôt que sur l'apprentissage. On estime que l'AGI, ainsi que la majorité des tâches d'IA couramment appliquées, nécessitent une certaine forme d'apprentissage automatique.

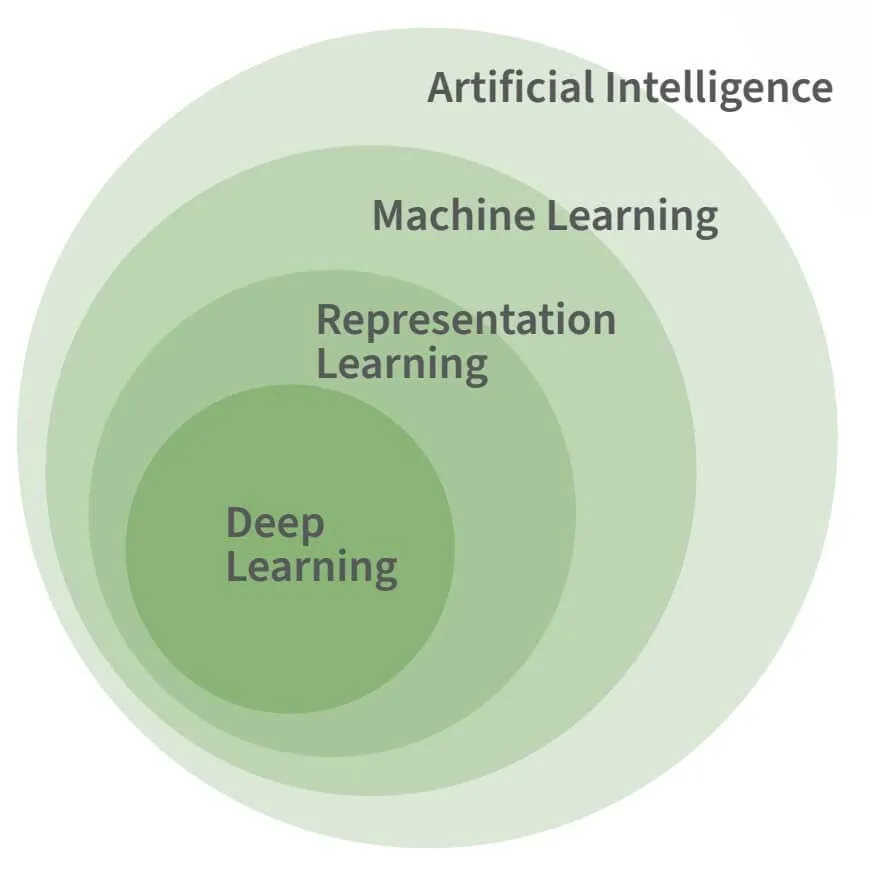
Le rôle des Machine Learning
La figure ci-dessus illustre la relation entre l'IA, l'apprentissage automatique et l'apprentissage profond. L'apprentissage profond est une forme spécifique d'apprentissage automatique et, bien que l'apprentissage automatique soit considéré comme nécessaire pour la plupart des tâches avancées de l'IA, il n'est pas en soi une caractéristique nécessaire ou déterminante de l'IA.
L'apprentissage automatique est nécessaire pour imiter les facettes fondamentales de l'intelligence humaine, plutôt que ses subtilités. Prenons, par exemple, le programme d'IA Logic Theorist développé par Allen Newell et Herbert Simon en 1955. Il a réussi à prouver 38 des 52 théorèmes initiaux de Principia Mathematica, sans aucun apprentissage.
IA, Machine Learning, et Deep Learning: Quelle est la différence ?
L'intelligence artificielle (IA), l'apprentissage machine (ML) et l'apprentissage profond (DL) sont souvent confondus, mais ils ont chacun leur propre signification. En comprenant la portée de ces termes, nous pouvons mieux comprendre les outils qui tirent parti de l'IA.
Intelligence artificielle (IA)
L'IA est un terme général qui englobe les systèmes capables d'automatiser le raisonnement et de se rapprocher de l'esprit humain. Ce terme englobe des sous-disciplines telles que la ML, la RL et la DL. L'IA peut se référer à des systèmes qui suivent des règles explicitement programmées ainsi qu'à ceux qui acquièrent de manière autonome une compréhension à partir de données. Cette dernière forme, qui apprend à partir de données, est à la base de technologies telles que les voitures auto-conduites et les assistants virtuels.
Machine Learning (ML)
La ML est une sous-discipline de l'IA dans laquelle les actions du système sont apprises à partir des données plutôt que d'être explicitement dictées par les humains. Ces systèmes peuvent traiter des quantités massives de données pour apprendre à représenter et à répondre de manière optimale à de nouvelles instances de données.
Vidéo : Machine Learning Principes fondamentaux pour les professionnels de la cybersécurité
Representation Learning (RL)
Le RL, souvent négligé, est crucial pour de nombreuses technologies d'IA utilisées aujourd'hui. Il implique l'apprentissage de représentations abstraites à partir de données. Par exemple, transformer des images en listes de nombres de longueur constante qui capturent l'essence des images originales. Cette abstraction permet aux systèmes en aval de mieux traiter les nouveaux types de données.
Deep Learning (DL)
La DL s'appuie sur la ML et la RL en découvrant des hiérarchies d'abstractions qui représentent les entrées de manière plus complexe. Inspirés du cerveau humain, les modèles DL utilisent des couches de neurones dont les poids synaptiques sont adaptables. Les couches plus profondes du réseau apprennent de nouvelles représentations abstraites, ce qui simplifie des tâches telles que la catégorisation d'images et la traduction de textes. Il est important de noter que si la DL est efficace pour résoudre certains problèmes complexes, elle n'est pas une solution universelle pour automatiser l'intelligence.
Référence : "Deep Learning," Goodfellow, Bengio & Courville (2016)
Techniques d'apprentissage en IA
Il est beaucoup plus difficile de créer des programmes qui reconnaissent la parole ou trouvent des objets dans des images, bien que ces tâches soient relativement faciles à réaliser pour les humains. Cette difficulté provient du fait que, bien que cela soit intuitivement simple pour les humains, nous ne pouvons pas décrire un ensemble de règles simples qui permettraient d'identifier des phonèmes, des lettres et des mots à partir de données acoustiques. C'est pour la même raison que nous ne pouvons pas définir facilement l'ensemble des caractéristiques des pixels qui distinguent un visage d'un autre.

La figure de droite, tirée de l'article d'Oliver Selfridge de 1955, Pattern Recognition and Modern Computers, montre que les mêmes données d'entrée peuvent conduire à des résultats différents, selon le contexte. Ci-dessous, le H de THE et le A de CAT sont des ensembles de pixels identiques, mais leur interprétation en tant que H ou A repose sur les lettres environnantes plutôt que sur les lettres elles-mêmes.
C'est pourquoi les succès sont plus nombreux lorsqu'on permet aux machines d'apprendre à résoudre des problèmes plutôt que d'essayer de prédéfinir ce à quoi ressemble une solution.
Les algorithmes de ML ont le pouvoir de trier les données en différentes catégories. Les deux principaux types d'apprentissage, supervisé et non supervisé, jouent un rôle important dans cette capacité.
Apprentissage supervisé
L'apprentissage supervisé apprend à un modèle à partir de données étiquetées, ce qui lui permet de prédire les étiquettes pour de nouvelles données. Par exemple, un modèle exposé à des images de chats et de chiens peut classer de nouvelles images. Bien qu'il ait besoin de données de formation étiquetées, il étiquette efficacement les nouveaux points de données.

Apprentissage non supervisé
D'autre part, l'apprentissage non supervisé fonctionne avec des données non étiquetées. Ces modèles apprennent des schémas dans les données et peuvent déterminer où les nouvelles données s'intègrent dans ces schémas. L'apprentissage non supervisé ne nécessite pas de formation préalable et permet d'identifier les anomalies, mais peine à leur attribuer des étiquettes.
Les deux approches offrent une gamme d'algorithmes d'apprentissage, qui s'élargit constamment au fur et à mesure que les chercheurs en développent de nouveaux. Les algorithmes peuvent également être combinés pour créer des systèmes plus complexes. Savoir quel algorithme utiliser pour un problème spécifique est un défi pour les scientifiques des données. Existe-t-il un algorithme supérieur capable de résoudre tous les problèmes ?

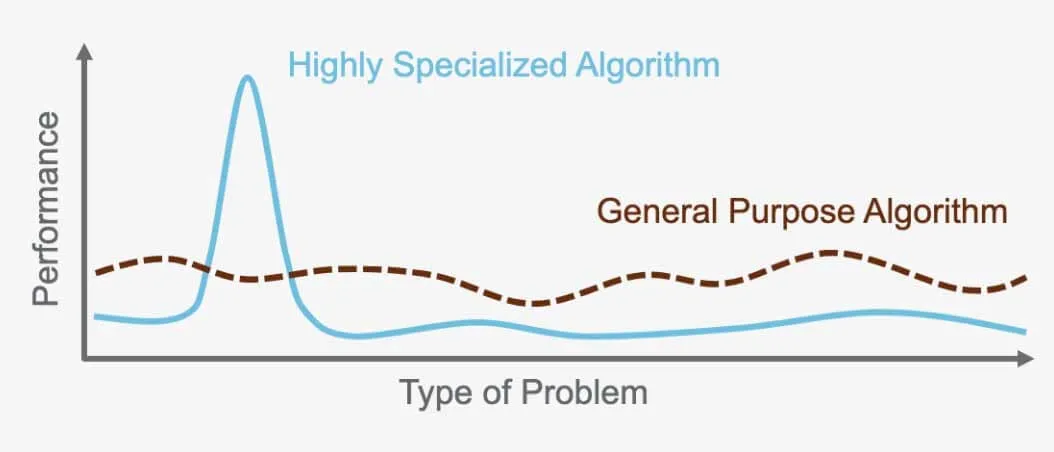
Le théorème du "No Free Lunch " : il n'existe pas d'algorithme universel
Le théorème "No Free Lunch " stipule qu'il n'existe pas d'algorithme parfait qui surpasse tous les autres pour chaque problème. Au contraire, chaque problème nécessite un algorithme spécialisé, adapté à ses besoins spécifiques. C'est pourquoi il existe tant d'algorithmes différents. Par exemple, un réseau neuronal supervisé est idéal pour certains problèmes, tandis que le regroupement hiérarchique non supervisé fonctionne mieux pour d'autres. Il est important de choisir le bon algorithme pour la tâche à accomplir, car chacun d'entre eux est conçu pour optimiser les performances en fonction du problème et des données utilisés.
Par exemple, l'algorithme utilisé pour la reconnaissance d'images dans les voitures autonomes ne peut pas être utilisé pour traduire des langues. Chaque algorithme sert un objectif spécifique et est optimisé pour le problème qu'il a été créé pour résoudre et les données sur lesquelles il opère.
Choisir le bon algorithme de Machine Learning
Choisir le bon algorithme en tant que data scientist est un mélange d'art et de science. En examinant l'énoncé du problème et en comprenant parfaitement les données, le data scientist peut être guidé dans la bonne direction. Il est essentiel de reconnaître qu'un mauvais choix peut conduire non seulement à des résultats sous-optimaux, mais aussi à des résultats complètement inexacts. Regardez l'exemple ci-dessous :
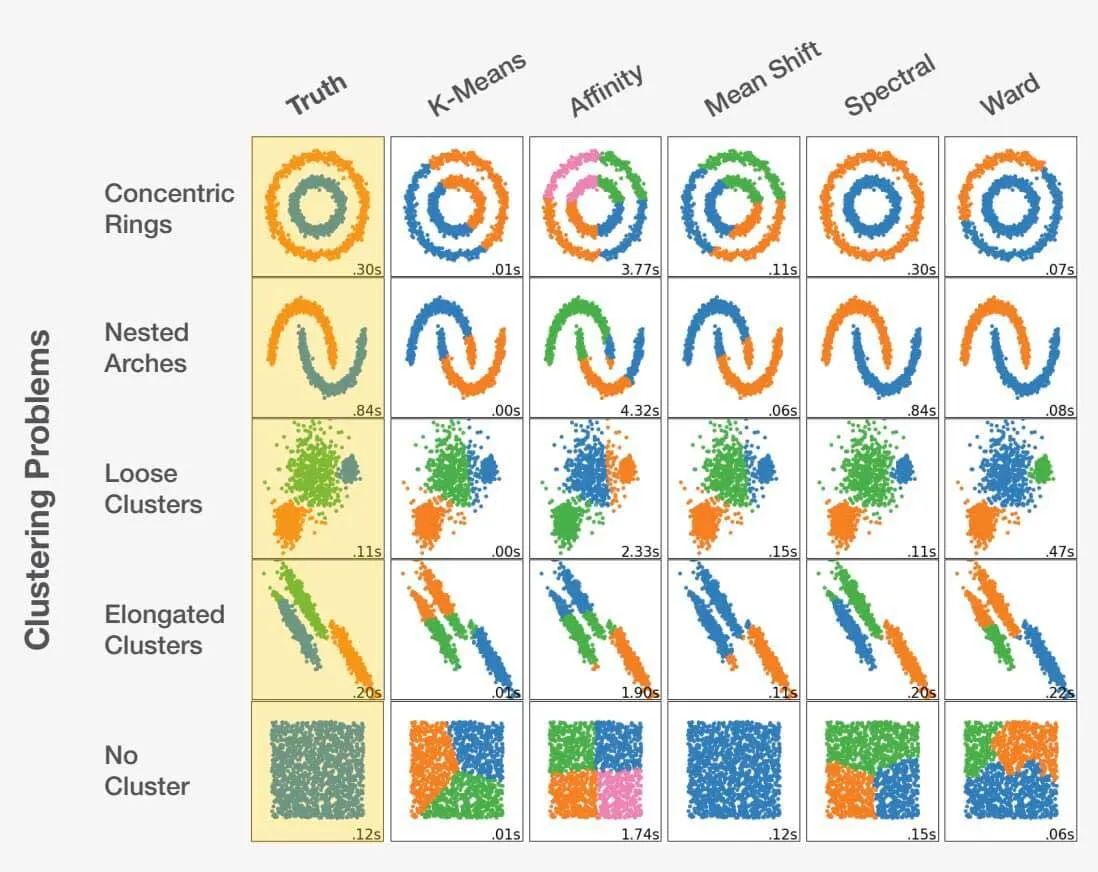
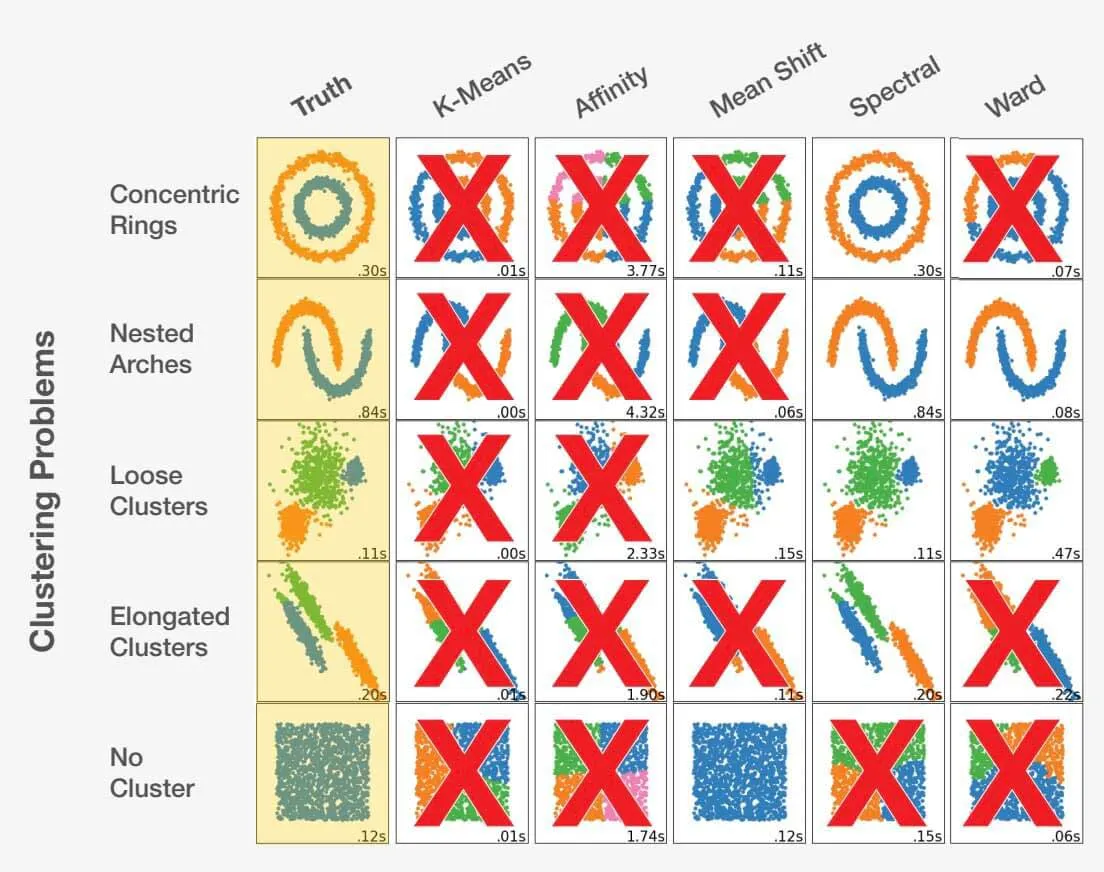
Adapté de scikit-learn.org.
Le choix du bon algorithme pour un ensemble de données peut avoir un impact significatif sur les résultats obtenus. Pour chaque problème, il existe un choix d'algorithme optimal, mais plus important encore, certains choix peuvent conduire à des résultats défavorables. Cela souligne l'importance cruciale de la sélection de l'approche appropriée pour chaque problème spécifique.
Comment mesurer le succès d'un algorithme ?
Choisir le bon modèle en tant que scientifique des données ne se limite pas à la précision. Si la précision est importante, elle peut parfois masquer les véritables performances d'un modèle.

Considérons un problème de classification avec deux étiquettes, A et B. Si l'étiquette A est beaucoup plus probable que l'étiquette B, un modèle peut atteindre une grande précision en choisissant toujours l'étiquette A. Cependant, cela signifie qu'il n'identifiera jamais correctement quelque chose comme étant l'étiquette B. La précision seule n'est donc pas suffisante si nous voulons trouver des cas B. Heureusement, les scientifiques des données disposent d'autres mesures pour optimiser et mesurer l'efficacité d'un modèle.
L'une de ces mesures est la précision, qui évalue le degré d'exactitude d'un modèle à deviner une étiquette particulière par rapport au nombre total de suppositions. Les scientifiques des données qui visent une précision élevée construisent des modèles qui évitent de générer de fausses alertes.

Mais la précision ne nous donne qu'une partie de l'information. Elle ne permet pas de savoir si le modèle ne parvient pas à identifier les cas qui sont importants pour nous. C'est là que le rappel entre en jeu. Recall mesure la fréquence à laquelle un modèle trouve correctement une étiquette particulière par rapport à toutes les instances de cette étiquette. Les scientifiques des données qui visent un rappel élevé construiront des modèles qui ne manqueront pas les cas importants.

En suivant et en équilibrant à la fois la précision et le rappel, les scientifiques des données peuvent mesurer et optimiser efficacement leurs modèles.