

Vous connaissez ce moment où quelqu'un dit "Branchons simplement ChatGPT sur le SOC " - et tout le monde acquiesce comme si c'était tout à fait normal ? Oui, ce billet traite de ce qui se passe après ce moment.
Parce qu'aussi cool que cela puisse paraître, ajouter GenAI à un SOC n'est pas de la magie. C'est désordonné. C'est gourmand en données. Et si vous ne mesurez pas ce qui se passe réellement sous le capot, vous risquez de finir par automatiser la confusion.
Nous avons donc décidé de le mesurer.
La GenAI dans le SOC : une idée géniale, une réalité difficile
Commençons par l'évidence : l'IA est aujourd'hui omniprésente dans le domaine de la sécurité.
Chaque présentation de SOC comporte une bulle "Assistant GenAI". Mais c'est la façon dont ces assistants se comportent réellement lorsqu'ils sont confrontés à des flux de travail SOC réels qui constitue le véritable test.
Le serveur MCP de Vectra est le contrôleur aérien de tous vos agents AI.
Il relie votre LLM (par exemple ChatGPT ou Claude) à vos outils de sécurité (et à leurs données !) - dans ce cas, Vectra AI
Le MCP orchestre l'enrichissement, la corrélation, le confinement et le contexte, permettant à votre agent d'IA d'interagir directement avec les signaux importants au lieu de se perdre dans les tableaux de bord.
Et comme nous souhaitons que chacun puisse tirer parti de ces fonctionnalités et en faire l'expérience, nous avons mis à disposition deux serveurs MCP qui vous permettent de connecter n'importe quelle plateforme Vectra plateforme vos flux de travail d'IA.
- ☁️ RUX - notre SaaS : http://github.com/vectra-ai-research/vectra-ai-mcp-server
- 🖥️ QUX - notre version sur site : http://github.com/vectra-ai-research/vectra-ai-mcp-server-qux
Si vous vous êtes dit : "J'aimerais pouvoir connecter mon LLM à ma pile de sécurité et voir ce qui se passe", c'est désormais possible. Pas de problèmes de licence, pas de NDA, il suffit de le brancher et de jouer.
Chez Vectra AI, nous croyons sincèrement que GenAI + MCP changeront fondamentalement le mode de fonctionnement des SOC.
Il ne s'agit pas d'une idée "à venir", c'est déjà le cas et nous veillons à ce que les utilisateurs de Vectra AI soient parfaitement équipés pour tirer parti de ce changement.
C'est également la raison pour laquelle nous passons beaucoup de temps à discuter avec nos clients, nos prospects et nos partenaires, afin de comprendre la rapidité avec laquelle ces technologies évoluent et ce que signifie réellement l'expression "LLM-ready" dans un SOC réel.
Nous avons donc décidé de le mesurer.
Car si l'IA générative est appelée à transformer les opérations de sécurité, nous devons avoir la certitude absolue que notre plateforme, nos données et nos intégrations MCP s'adaptent parfaitement à ce nouvel environnement. Mesurer l'efficacité n'est pas une simple activité secondaire : c'est ainsi que nous assurons la pérennité du SOC.
Il ne s'agit pas d'avoir plus de données, mais de meilleures données.
Soyons francs : la GenAI sans données de qualité, c'est comme engager Sherlock Holmes et lui mettre un bandeau sur les yeux.
Chez Vectra AI, les données sont le facteur de différenciation. Deux choses les rendent spéciales :
- Détections basées sur l'IA : elles s'appuient sur des années de recherche sur les comportements des attaquants, et non sur des anomalies. Elles sont conçues pour être robustes, ce qui signifie qu'elles restent efficaces même si les attaquants changent d'outils. Chaque détection se concentre sur l'intention et le comportement plutôt que sur des indicateurs statiques, ce qui donne aux équipes SOC l'assurance que ce qu'elles voient est réel et pertinent.
- Métadonnées de réseau enrichies : télémétrie à contexte élevé couvrant des environnements hybrides, structurée et corrélée de manière à être lisible par la machine et immédiatement exploitable.
C'est le genre de données que la GenAI peut réellement utiliser. Introduisez-les dans un LLM et il commencera à raisonner comme un analyste chevronné. Donnez-lui des logs bruts, et vous obtiendrez une hallucination très confiante sur le DNS.
Alors, comment évaluer un analyste en IA ?
Il s'avère que l'on ne peut pas simplement lui demander de "trouver les méchants plus rapidement".
Vous devez mesurer la façon dont il raisonne. Et lorsque vous traitez avec un agent d'IA avec MCP, il y a principalement 3 choses que vous pouvez influencer :
- Le modèle (GPT-5, Claude, Deepseek, etc.)
- L'invite (comment vous lui demandez d'agir - ton, structure, objectifs)
- Le MCP lui-même (comment il s'intègre dans votre système de détection)
Chacun de ces éléments peut faire bouger l'aiguille de la performance.
Modifiez légèrement l'invite, et soudain votre analyste IA "confiant" oublie comment épeler "PowerShell".
Si vous changez de modèle, le temps de latence double.
Changez l'intégration du MCP et la moitié de votre contexte disparaît.
C'est pourquoi nous avons construit un banc d'essai reproductible - évaluation automatisée, scénarios SOC réels, et une pincée d'honnêteté brutale.
Le banc d'essai (a.k.a. "nous l'avons vraiment essayé")
Pour le premier essai, nous avons volontairement simplifié les choses : tâches de niveau 1, raisonnement léger (deux sauts maximum), pas de chorégraphie multi-agents fantaisiste.
La pile se présentait comme suit :
- n8n pour le prototypage rapide et l'automatisation
- Serveur Vectra QUX MCP pour accéder aux données et utiliser la plateforme.
- Une invite SOC minimale (en gros : "Vous êtes un analyste en IA. Aidez-nous. Si vous ne savez pas, dites-le").
- Évaluation alimentée par un LLM comparer les réponses attendues aux réponses réelles
Mais il ne s'agissait pas d'une simple expérience. Nous avons testé 28 tâches SOC réelles - celles auxquelles les analystes sont confrontés chaque jour. Des tâches telles que :
- Liste des hôtes en état élevé ou critique
- Extraction des détections pour des points d'extrémité spécifiques (piper-desktop, deacon-desktop, etc.)
- Vérification des détections de commande et de contrôle liées à des adresses IP ou à des domaines
- Recherche d'exfiltrations de plus de 1 Go
- Marquage et suppression des artefacts de l'hôte
- Recherche de comptes dans les quadrants de risque "élevé" ou "critique".
- Recherche de comptes "Admin" impliqués dans les opérations d'EntraID
- Interroger les détections avec des empreintes JA3 spécifiques
- Affectation d'analystes à des hôtes ou à des détections
En gros, tout ce qu'un analyste SOC de niveau 1 ou 2 est susceptible de toucher lors d'un mardi matin chargé.
Chaque exécution a été notée en fonction de la correction, de la vitesse, de l'utilisation de jetons et de l'activité de l'outil, le tout sur une échelle de 1 à 5.
Qu'est-ce qui fait un bon agent GenAI ?
L'évaluation de la GenAI au sein d'un SOC ne consiste pas à déterminer quel modèle semble le plus intelligent. Il s'agit de savoir avec quelle efficacité il pense, agit et apprend. Un bon agent d'IA se comporte comme un analyste pointu - il ne se contente pas d'obtenir la bonne réponse, il y parvient efficacement. Voici ce qu'il faut rechercher :
- Utilisation efficace des jetons. Moins il faut de mots pour raisonner, mieux c'est. Les modèles longs gaspillent de l'espace de calcul et de contexte.
- Des appels d'outils intelligents. Lorsqu'un modèle utilise toujours le même outil, il dit en fait "laissez-moi réessayer". Les meilleurs savent quand et comment utiliser un outil - un minimum d'essais et d'erreurs, un maximum de précision.
- La vitesse sans le laisser-aller. La rapidité est une bonne chose, mais seulement si la précision est au rendez-vous. Le modèle idéal équilibre la réactivité et la profondeur du raisonnement.
En bref : votre meilleur analyste d'IA ne se contente pas de parler, il réfléchit efficacement.
Voici ce que nous avons trouvé :

Faits marquants et enseignements pratiques
- Le GPT-5 gagne en précision et en profondeur de raisonnement, mais il est lent et cher. À utiliser lorsque la précision est plus importante que la vitesse.
- Claude Sonnet 4.5 offre le meilleur équilibre global : précision, vitesse et efficacité. Idéal pour les SOC de production.
- Claude Haiku 4.5 est parfait pour le triage rapide : rapide, bon marché et "suffisamment bon" pour les décisions de première ligne.
- Deepseek 3.1 est le champion du rapport qualité-prix : des performances impressionnantes pour une fraction du prix.
- Grok Code Fast 1 est destiné aux flux de travail nécessitant beaucoup d'outils (automatisation, enrichissement, etc.), mais surveillez votre facture de jetons.
- GPT-4.1... disons qu'il n'est pas invité à revenir pour une autre période de travail.
Et parce que tout bon article a besoin de graphiques, en voici quelques-uns :
Comparaison des scores de correction

GPT-5 est techniquement le vainqueur avec 4.32/5, mais honnêtement ? Claude Sonnet 4.5 et Deepseek 3.1 sont à égalité à 4.11 et vous ne remarquerez probablement pas la différence. Le vrai coup de théâtre ? GPT 4.1 est complètement à la ramasse avec 2.61/5. C'est à se demander si ce n'est pas là qu'est le problème. N'utilisez pas cette version pour des questions de sécurité.
Temps d'exécution
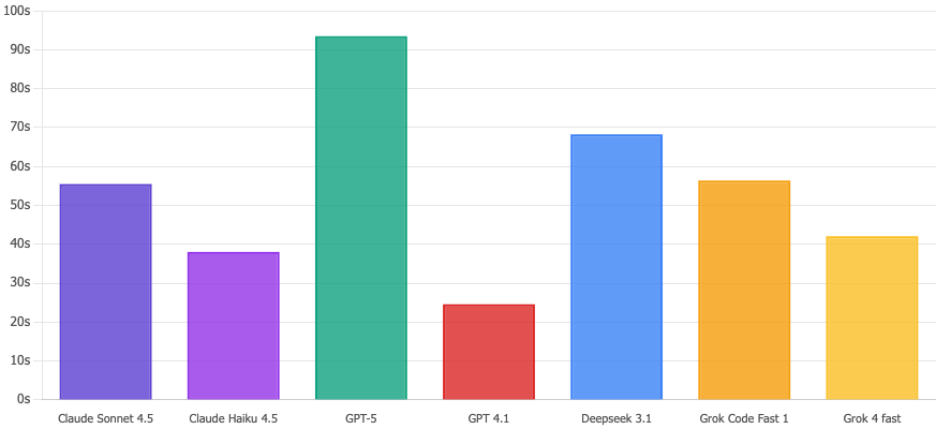
Claude Haiku 4.5 est et traite ces requêtes en 38 secondes. Pendant ce temps, GPT-5 se promène tranquillement en 93 secondes, soit 2,5 fois plus lentement. En cas d'incident de sécurité potentiel, ces secondes supplémentaires paraissent interminables. Haiku s'en charge.
Matrice de proposition de valeur
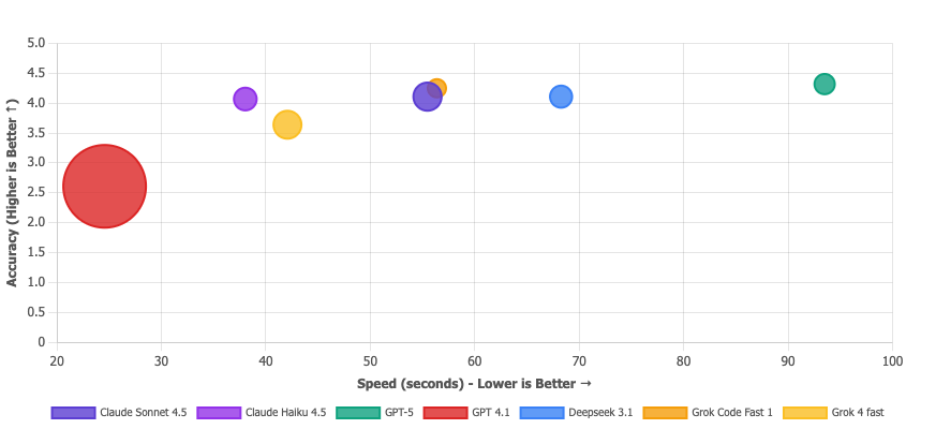
Une bulle plus grande = moins de jetons utilisés. La bulle de GPT 4.1 est énorme, mais ce n'est pas une flexion - c'est comme dire "j'ai fini l'examen super vite" alors que vous l'avez raté. Un produit bon marché et erroné n'est pas une proposition de valeur, c'est juste... erroné. Les modèles que vous voulez vraiment sont dans le coin supérieur droit: Deepseek 3.1 (efficace ET précis), Claude Sonnet 4.5 (une bête équilibrée) et Grok Code Fast (solide dans l'ensemble). La micro-bulle de GPT-5 confirme qu'il s'agit de l'option la plus chère.
Qu'avons-nous appris ?
- La précision n'est pas tout. Un modèle qui est légèrement plus précis mais qui prend deux fois plus de temps - et qui brûle cinq fois plus de jetons - n'est peut-être pas la meilleure option. Dans un SOC, l'efficacité et l'échelle font partie de la précision.
- L'utilisation des outils est une fenêtre sur le raisonnement. "Si un LLM a besoin de dix appels d'outils pour répondre à une question simple, il ne fait pas preuve de rigueur, il est perdu. Les modèles les plus performants ne se contentent pas d'obtenir la bonne réponse, ils y parviennent efficacement, en utilisant une ou deux requêtes intelligentes par le biais du MCP. L'utilisation de l'outil n'est pas une question de quantité, mais de rapidité avec laquelle le modèle trouve le bon chemin. Le LLM n'est pas toujours à blâmer. Un bon serveur MCP est essentiel pour une utilisation optimale des outils. Mais gardons l'évaluation du MCP pour plus tard.
- La conception des messages est sous-estimée. La plus petite modification dans la formulation peut faire varier les taux de précision ou d'hallucination de façon spectaculaire. Nous avons volontairement minimisé l'incitation, afin de disposer d'une base de référence pour les ajustements futurs, mais il est clair que les petits choix de conception ont des effets importants.
Conclusion (et petit rappel à la réalité)
La question n'est donc pas de savoir quel modèle remporte un concours de beauté. Bien sûr, le GPT-5 peut l'emporter sur Claude sur un critère ou un autre, mais ce n'est pas là l'essentiel.
La vraie leçon est que l 'évaluation de votre agent d'IA n'est pas facultative.
Si vous comptez vous appuyer sur la GenAI au sein de votre SOC - pour trier les alertes, résumer les incidents ou même appeler des actions de confinement - vous devez savoir comment elle se comporte, où elle échoue et comment elle évolue dans le temps.
L'IA sans évaluation n'est que de l'automatisation sans responsabilité.
Tout aussi important : vos outils de sécurité doivent parler le LLM.
Cela signifie des données structurées, des API propres et un contexte lisible par la machine - et non enfermé dans des tableaux de bord ou des silos de fournisseurs. Le modèle le plus avancé au monde ne peut pas raisonner s'il est alimenté par des données télémétriques à moitié cassées.
C'est pourquoi, chez Vectra AI, nous mettons un point d'honneur à ce que notre plateforme ainsi que notre serveur MCP — soient dès leur conception compatibles avec les grands modèles de langage (LLM). Les signaux que nous produisons ne sont pas uniquement destinés aux humains ; ils sont conçus pour être exploités par des machines, par des agents IA capables de raisonner, d'enrichir les données et d'agir.
Car dans la prochaine vague d'opérations de sécurité, il ne suffit pas d'utiliser l'IA - tout votre écosystème doit être compatible avec l'IA.
Le SOC du futur n'est pas seulement alimenté par l'IA. Il est mesuré par l'IA, connecté à l'IA et prêt pour l'IA.