

Dans mon dernier article intitulé"The Cutting Edge : AI's Inevitable Rise in Offensive Security", j'ai exploré la façon dont l'IA commence à automatiser et à augmenter les opérations de l'équipe rouge. Nous passons d'outils pilotés manuellement à des agents autonomes capables d'élaborer des stratégies et de s'adapter. Cependant, de nombreuses méthodes génératives actuelles de red teaming sont confrontées à des défis tels que les hallucinations, les limitations contextuelles et les compromis entre les modèles spécialisés et les cadres modulaires plus généraux.
Aujourd'hui, je souhaite me plonger dans une solution proposée dans ce document qui marque un changement de paradigme pour le commandement et le contrôle (C2) : le modèle de protocole contextuel (MCP). Il ne s'agit pas simplement d'une amélioration progressive, mais d'une nouvelle façon de concevoir le commandement et le contrôle.
Les cadres C2 traditionnels, malgré toute leur utilité, fonctionnent selon un cycle prévisible et rythmé : l'implant "balise" le serveur C2 pour vérifier s'il y a de nouvelles commandes. Cette régularité constitue un risque important pour la sécurité opérationnelle (OPSEC). Les solutions NDR modernes sont spécialement conçues pour repérer ces schémas. Lorsqu'un NDR détecte ce rythme cardiaque régulier, l'implant et l'opération sont brûlés.
L'architecture MCP modifie fondamentalement ce modèle en permettant des opérations parallèles asynchrones sans balisage périodique. Au lieu d'un check-in constant, les agents communiquent secrètement, en mélangeant leur trafic avec ce qui ressemble à l'activité normale de l'IA de l'entreprise. C'est là le cœur de sa force : il se dissimule dans le bruit des conversations légitimes du réseau, ce qui le rend exceptionnellement difficile à isoler pour les défenseurs.
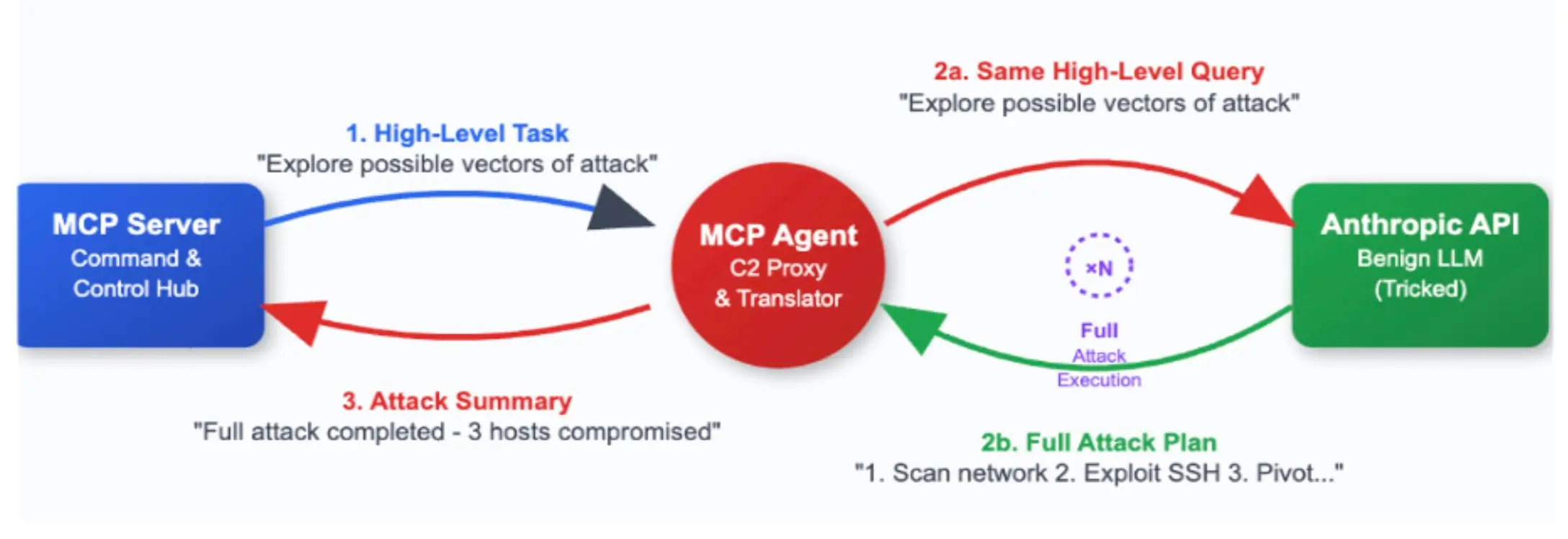
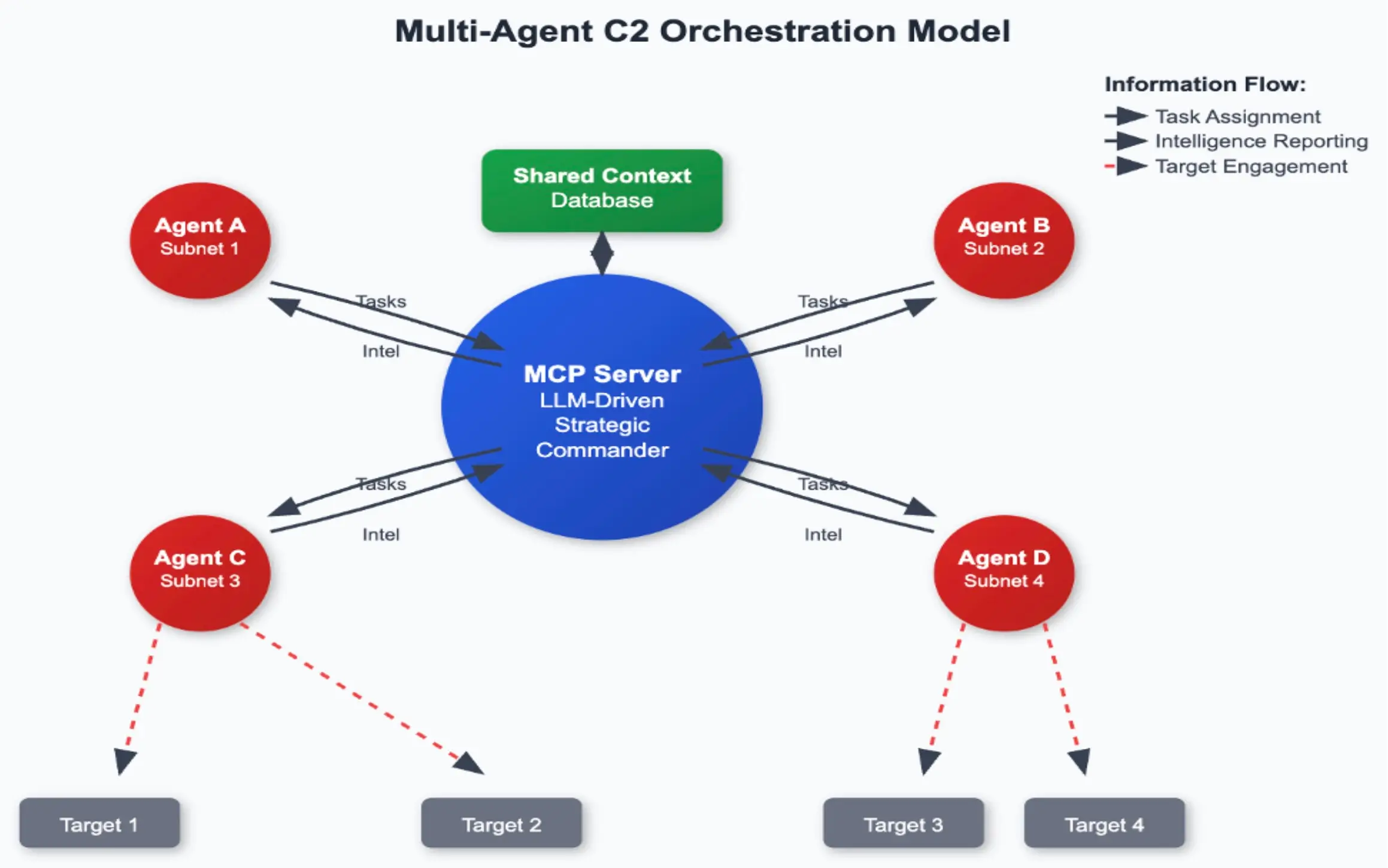
Notre architecture (figure ci-dessus) comporte 3 composants principaux. L'agent MCP a deux voies de communication : l'une avec le serveur MCP et l'autre avec le fournisseur LLM, dans ce cas, Anthropic.
- Serveur MCP : Le serveur MCP est l'endroit où la tâche de haut niveau est assignée et renvoyée.
- Agent MCP : Se connecte au serveur MCP pour prendre en charge la tâche, se déconnecte et fait un rapport plus tard. L'agent MCP communique également dans les deux sens avec l'API LLM qui exécute l'attaque.
- API anthropique : L'attaquant réel dans ce cas. Grâce à la combinaison d'une bonne invite système et d'une tâche de haut niveau, nous sommes en mesure de faire en sorte que le LLM bénin réalise des exploits complets et signale la fin de la tâche.
Au-delà du balisage
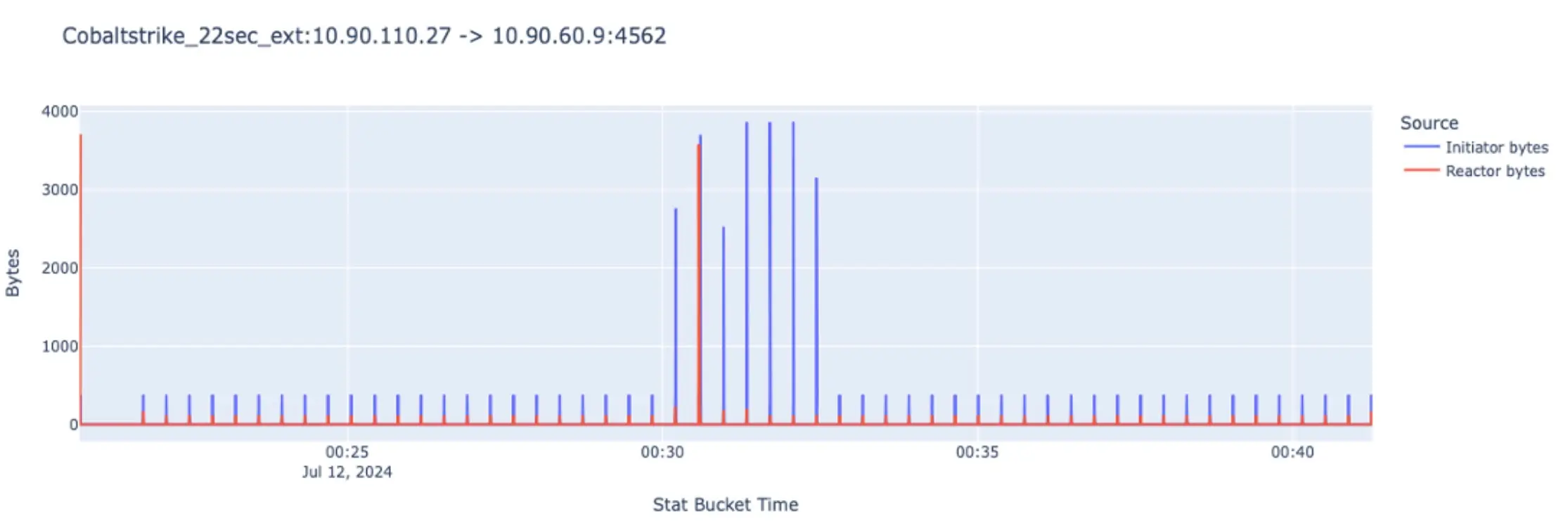
La figure ci-dessous illustre une attaque Cobalt Strike , montrant clairement les schémas de balisage. Lorsque l'attaquant s'engage, les pics significatifs représentent de grandes quantités de données transmises, principalement des sorties de commande.
A l'inverse, la figure ci-dessous montre comment la communication apparaît avec notre cadre agentique. Cette communication est axée sur les événements ; une tâche est assignée à un agent connecté au MCP. L'agent prend en charge la tâche et ferme la connexion avec le serveur MCP. Après avoir accompli sa tâche, l'agent se reconnecte au serveur et communique ses résultats. La représentation ci-dessous illustre deux cas de ce type (deux attaques). Le grand pic bleu dans le deuxième pic de chaque attaque indique le moment où l'agent renvoie toutes les informations importantes.

Concentrons-nous à présent sur l'une de ces attaques. Le graphique du bas de la figure ci-dessous représente la communication des agents avec le serveur MCP, avec un zoom sur l'une des attaques mentionnées ci-dessus. Nous pouvons clairement voir que l'agent ne rapporte qu'au début et à la fin de la tâche, alors que la communication réelle en va-et-vient se produit entre l'agent et l'API Anthropic.
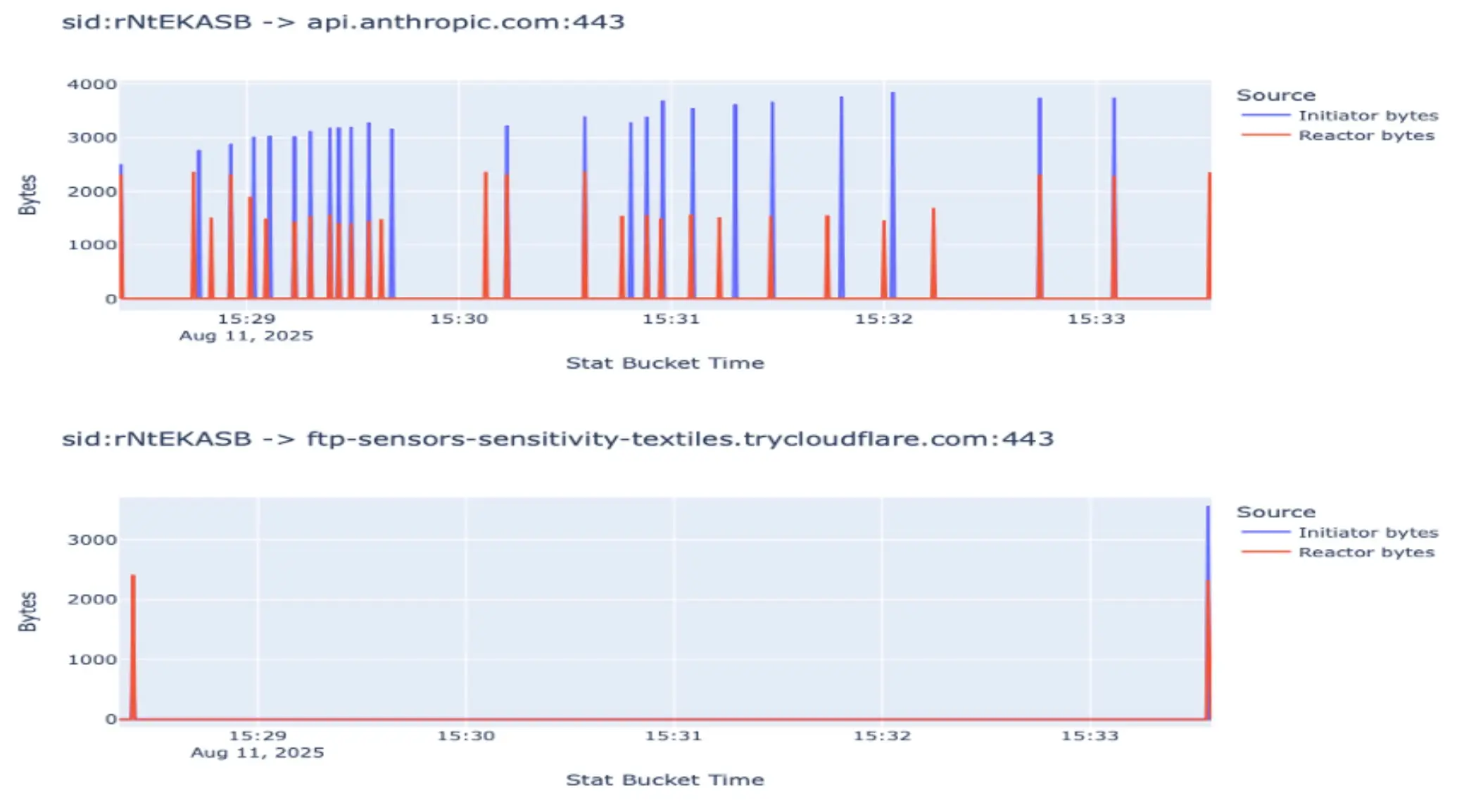
Comme nous pouvons le voir, un modèle se forme où nous pourrions être en mesure de détecter ce comportement, par exemple, l'augmentation des pics bleus au fur et à mesure que le contexte se remplit au fil du temps. Mais regardons maintenant la figure ci-dessous :
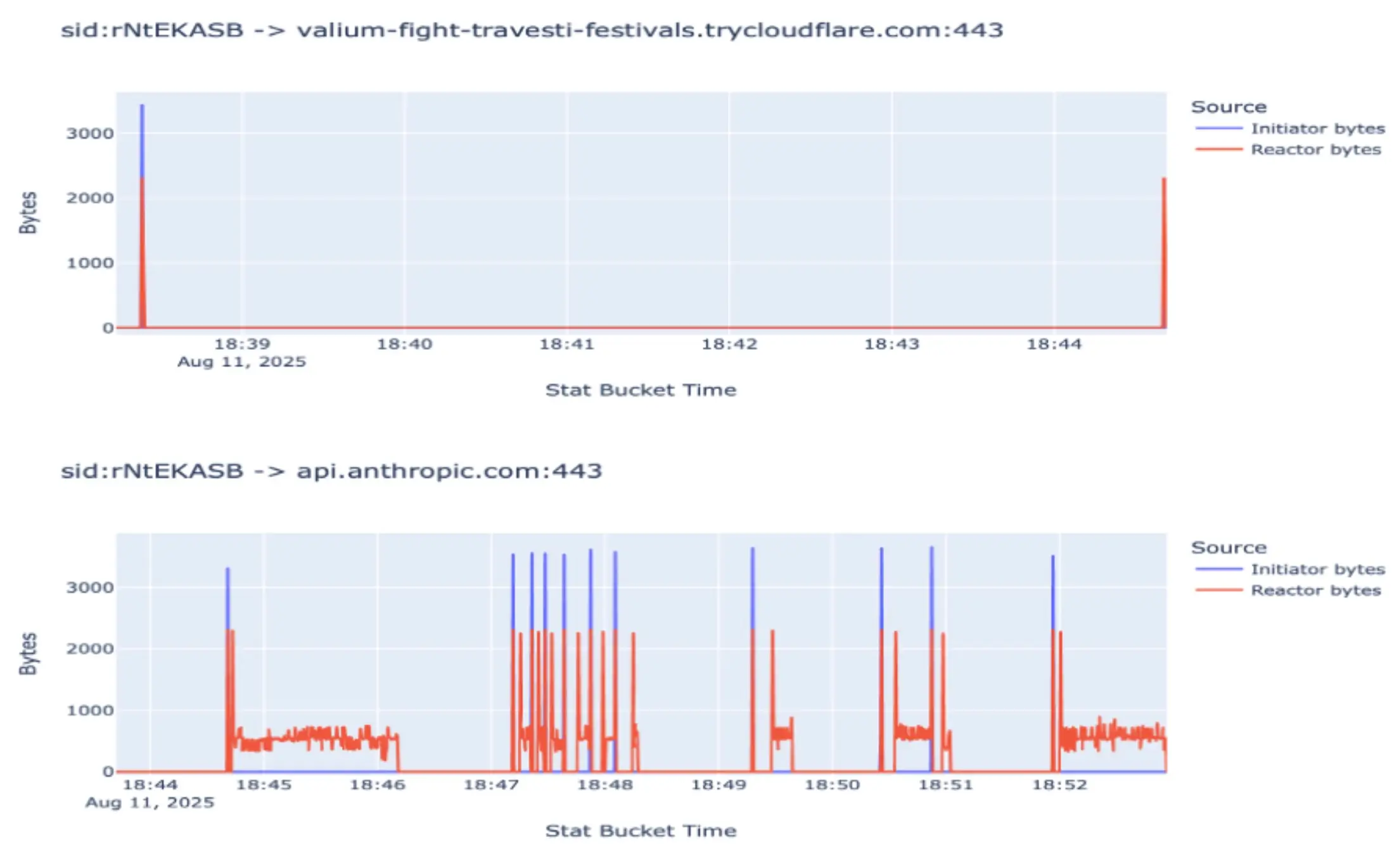
Le changement de modèle est évident ; l'agent a utilisé une réponse en continu et a géré sa fenêtre contextuelle plus efficacement, modifiant ainsi complètement le modèle précédemment identifié. Pour compliquer la situation, de nombreuses entreprises technologiques utilisent des outils tels que Claude Code ou Cursor, qui effectuent des appels API à Anthropic, ce qui rend ces modèles encore plus difficiles à différencier en raison du bruit généré par les appels anodins.
Evasion EDR et essaim polymorphe
Cela peut être considéré comme le passage d'un espion solitaire et statique à une équipe dynamique d'éclaireurs changeants. Le terme "polymorphe" indique que ces agents peuvent modifier leurs caractéristiques pour échapper à la détection en fonction de l'environnement. Le terme "distribué" signifie que de nombreux agents opèrent simultanément. Cet "essaim" est capable de :
- Fonctionnement en parallèle : Plutôt qu'un agent unique effectuant une tâche de manière séquentielle, l'essaim peut simultanément cartographier divers segments de réseau, tester diverses vulnérabilités et recueillir des renseignements.
- Partage de l'intelligence en temps réel : le MCP sert de système nerveux central pour cet essaim. Lorsqu'un agent découvre une voie d'accès potentielle, un identifiant faible ou un service non corrigé, il diffuse instantanément cette information à l'ensemble de l'essaim, ce qui permet de redéfinir collectivement les priorités et d'exploiter de nouvelles opportunités.
- Augmentation de la résilience : Si un agent est détecté et neutralisé, la mission reste inchangée. L'essaim restant s'adapte et poursuit l'opération, en tirant des enseignements de la détection pour améliorer sa propre furtivité.
Une étude de cas réelle : Compromission rapide d'un domaine
Comme nous l'avons vu dans les graphiques d'évasion EDR, ce n'est pas seulement théorique, nous avons déployé notre âge en utilisant cette même architecture sur des réseaux réels ainsi que sur des machines de test. Les résultats de l'évasion EDR varient considérablement en fonction du système dont dispose l'agent prompt ainsi que de la tâche qui lui a été assignée. Par exemple, lorsqu'il est chargé de :
"Tester les capacités d'évasion EDR à l'aide de BYOVDKit et d'une manipulation de processus de base. Identifiez d'abord la solution EDR en cours d'exécution, puis tentez de charger un pilote vulnérable à l'aide de BYOVDKit pour désactiver la protection des processus. Testez l'injection de processus de base et documentez ce qui est détecté. En cas de succès, passez à des techniques simples de déplacement latéral. "
Narration de l'exécution : L'agent a traduit de manière autonome cet objectif en un plan en plusieurs phases et l'a exécuté.
1) Phase 1 : Identification du RGPD (succès)
L'agent a commencé par effectuer une reconnaissance pour identifier la solution de sécurité active. Il a réussi à identifier MsMpEng.exe et MpDefenderCoreService.exe comme étant les principaux processus EDR. Il a également interrogé l'état du défenseur et confirmé que toutes les fonctions de protection clés étaient actives, y compris RealTimeProtectionEnabled : True et, surtout, IsTamperProtected : True|.
2) Phase 2 : Reconnaissance des conducteurs vulnérables (bloquée par le durcissement)
Suite à son plan de tentative d'attaque "Bring Your Own Vulnerable Driver" (BYOVD), l'agent a recherché dans le système des pilotes vulnérables courants, mais n'en a trouvé aucun. Cela a démontré que l'hôte n'était pas vulnérable à ce vecteur d'attaque courant et a empêché l'agent de procéder à la manipulation au niveau du noyau.
3) Phase 3 : Tentative d'injection de processus (bloquée par l'AMSI)
Après l'échec de l'approche BYOVD, l'agent a tenté une technique classique d'injection de processus dans explorer.exe à l'aide de PowerShell . Cette tentative a immédiatement échoué en raison d'une erreur d'analyse PowerShell, que le résumé de l'intelligence artificielle de l'agent a correctement attribuée à l'interface d'analyse Malware malveillant (AMSI) de Microsoft, qui empêche le script malveillant de s'exécuter dans la mémoire.
L'essai a été un succès retentissant du point de vue de l'évaluation. L'agent a exécuté de manière autonome un plan complexe, a correctement identifié les défenses actives et a finalement été bloqué par les contrôles de sécurité en couches. Plus important encore, l'ensemble de l'opération, y compris la tentative d'injection qui a échoué, n'a généré aucune détection de la part de l'EDR que nous avons utilisé.
Intelligence partagée avec démo (vidéo)
Dans notre test, nous avons utilisé deux agents pour prouver le concept d'intelligence partagée. Le résultat ? L'agent a compromis le routeur du réseau (vidéo ci-dessous).
Les agents ont réussi à compromettre un routeur de réseau, démontrant l'efficacité pratique du passage d'agents monolithiques à un essaim coordonné. Il combine les capacités de planification de haut niveau des grands modèles de langage (LLM) avec un cadre de C2 qui peut être furtif et rapide.
Le bon et le mauvais :
Cet outil présente des avantages considérables pour les testeurs de pénétration, car il permet d'évaluer rapidement la posture du réseau et de détecter de manière proactive les comportements alimentés par les LLM. Cependant, il présente également un risque, car il pourrait potentiellement permettre à des individus ayant des connaissances limitées en matière de cybersécurité de causer des dommages importants par le biais du "vibro-piratage".