

UPDATE: Cet article a été mis à jour pour refléter les nouvelles informations obtenues en collaboration avec les équipes AWS S3 Replication, CloudTrail et Security.
Une stratégie de sauvegarde complète est la pierre angulaire de tout plan de reprise après sinistre. Mais comment distinguer une activité de sauvegarde légitime d'une exfiltration de données malveillante ?
Les cyberattaquants accèdent de plus en plus facilement aux planscloud , qui comprennent des fonctionnalités permettant d'effectuer des sauvegardes cloud. Je vais vous montrer ici comment ces outils peuvent être utilisés pour exfiltrer des données de l'environnement de production d'une organisation.
Dans ce blog, vous verrez comment un pirate peut abuser de la réplication S3 pour migrer efficacement vos données hors de votre environnement. J'espère que vous trouverez ce blog aussi divertissant à lire qu'il l'a été à créer.
Vous verrez cette attaque se dérouler dans des arcs narratifs distincts du point de vue de quatre acteurs différents énumérés ici.
- Le service de réplication S3Le service de réplication S3 est un service qui permet de répliquer les données S3 entre les différents buckets en suivant les ordres dictés par les règles de réplication.
- Le service de réplication S3 maléfiqueLe service de réplication S3 est un service maléfique, car ses pouvoirs sont utilisés de manière abusive pour copier des données vers des emplacements externes.
- L'attaquant qui prend le contrôle du service de réplication S3, le cooptant à des fins malveillantes et profitant de l'absence de journalisation pour passer inaperçu.
- Les membres de l'équipe SOC (centres d'opérations de sécurité) qui apprennent qu'ils sont partiellement aveugles aux mouvements de données via le service de réplication S3, mais qui peuvent désormais modifier leur stratégie de détection pour compenser.
Présentation du service de réplication S3, de ses capacités et de ses cas d'utilisation pour de bon
Le service AWS S3 n'est plus le "Simple Storage Service" qu'il était censé être. Avec des dizaines de fonctionnalités et d'intégrations, il est devenu le magasin de données de prédilection des entreprises clientes d'AWS. Il est également si compliqué qu'il est difficile de comprendre et donc de sécuriser toutes ses capacités. L'une des nombreuses fonctionnalités de S3 est la possibilité de copier les données entre les régions et les comptes, créant ainsi des sauvegardes actives de vos données.
Comme vous le verrez dans ce billet, cette fonctionnalité est propice aux abus et il peut être difficile d'en avoir une vision claire.

Le service de réplication d'AWS fait exactement ce que l'on pourrait penser : lorsqu'il est soumis à des règles, il copie les données S3 entre les buckets.
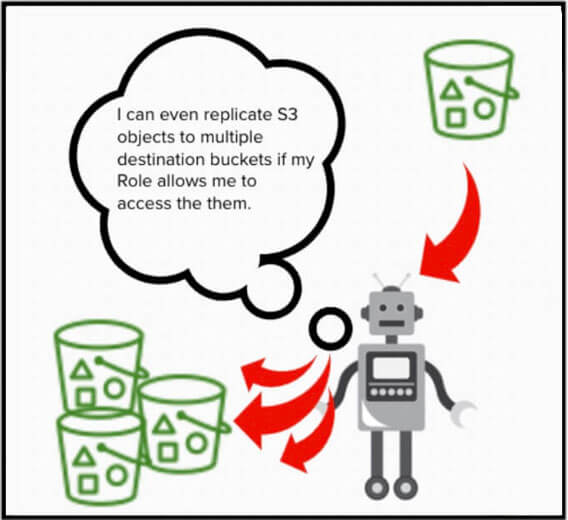
Le service reçoit ses ordres des règles de réplication. Vous pouvez configurer les règles pour indiquer au service de copier les données dans plusieurs godets, créant ainsi plusieurs répliques du même objet source.
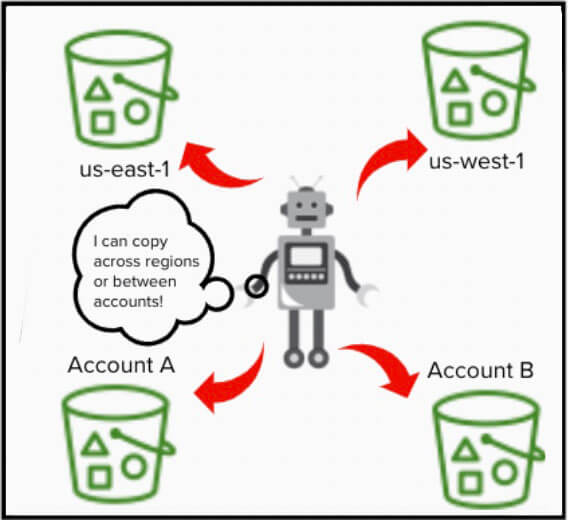
Il n'est même pas nécessaire que les buckets de destination se trouvent dans la même région ou sur le même compte que le bucket source.
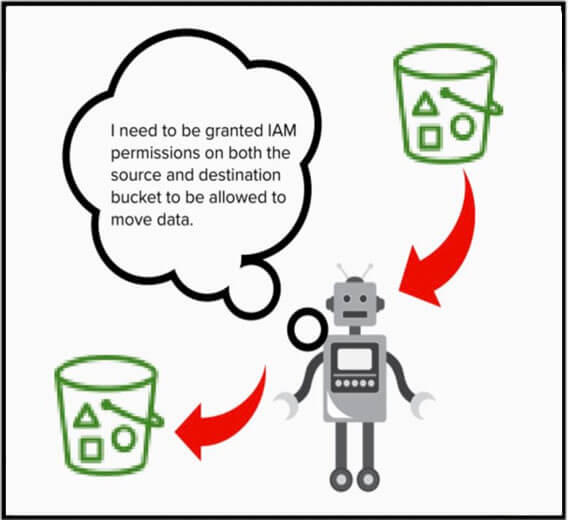
Ses capacités de réplication des données ne sont possibles que si le service dispose des autorisations nécessaires. Pour activer le service de réplication S3, vous devez le configurer de manière à ce qu'il assume un rôle IAM et qu'il reçoive des autorisations IAM lui permettant d'accéder aux buckets source et de destination.
Quelles sont les conséquences si un pirate obtient la possibilité d'utiliser la réplication S3 dans AWS ?

La réplication entre comptes peut aider les organisations à récupérer les données perdues. Toutefois, entre de mauvaises mains, le service de réplication permet à cybercriminels de siphonner des données vers des sites non fiables.

Le service de réplication S3 présente un fort potentiel d'abus et constitue donc une cible de choix pour les attaquants.

Si un attaquant parvenait à créer des règles de réplication, il pourrait ordonner au service de réplication S3 de copier des données vers un bac externe contrôlé par l'attaquant. Même s'il réside en dehors de l'organisation AWS de la victime.
Quelles sont les autorisations IAM requises pour la réplication externe ?
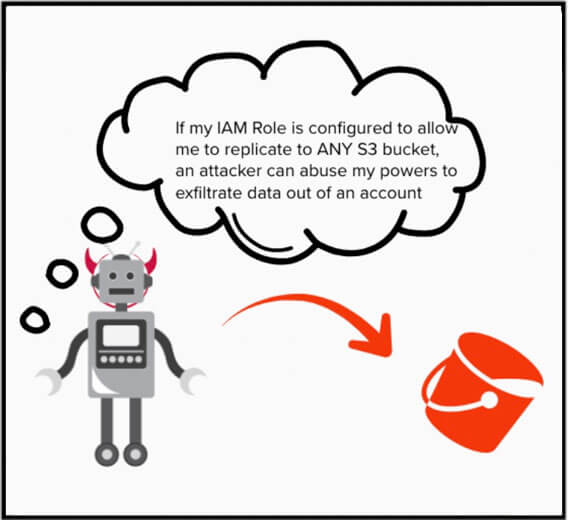
Le service de réplication S3 nécessite des autorisations sur les objets S3 pour obtenir l'objet du bac source et le répliquer vers le bac externe contrôlé par l'attaquant.
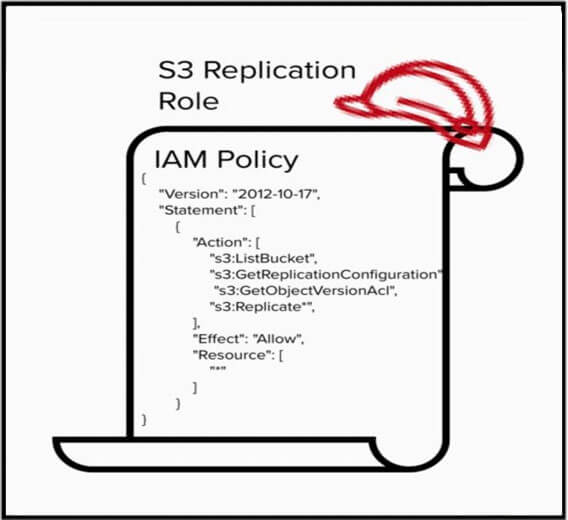
Voici un exemple de politique IAM qui définit les actions requises pour la réplication mais néglige d'étendre les permissions à une ressource, laissant le champ de la ressource à "*". Cette politique est tellement permissive qu'elle permet au service de réplication S3 de copier des objets dans n'importe quel panier, même ceux qui ne sont pas dans votre compte.

Dans le cas d'une politique trop permissive, un attaquant aurait besoin de pouvoir mettre à jour les règles de réplication, en ordonnant au service de réplication de copier les données dans un bac contrôlé par l'attaquant. Aucune autorisation n'est requise sur les objets eux-mêmes, mais seulement la possibilité de mettre à jour les règles.
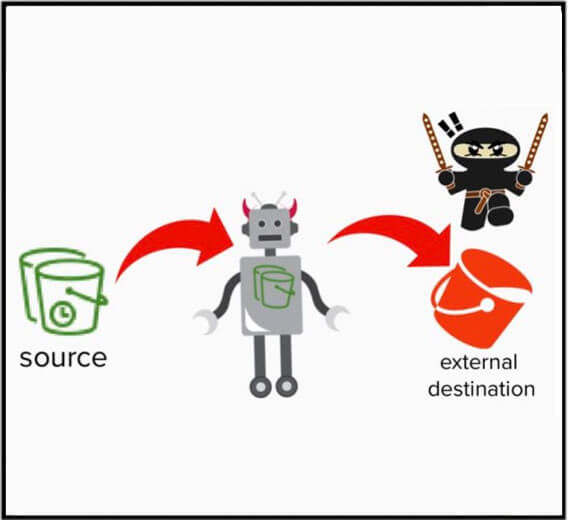
Pour résumer, au lieu de copier ou de déplacer directement des données hors d'un compte, le service de réplication S3 peut être utilisé par un attaquant pour effectuer ces mêmes actions en son nom, à la suite d'une règle de réplication malveillante. Il ne s'agit pas d'un bogue qui peut être corrigé, mais plutôt d'un type de vulnérabilité cloud appelé "abus de fonctionnalité".
Comment le service de réplication S3 enregistre-t-il ses activités ? Et comment cela permet-il à un attaquant de passer inaperçu ?
Le mouvement autorisé des données via le service de réplication S3 est peu transparent, ce qui rend particulièrement difficile la chasse à l'exfiltration de données, permettant à un attaquant de cacher son activité au vu et au su de tous dans votre environnement cloud .

Voyons quand et où le service de réplication écrit des événements sur CloudTrail en fonction de la configuration de votre plan de données (data-plane trail) et de la portée des seaux (bucket scoping).
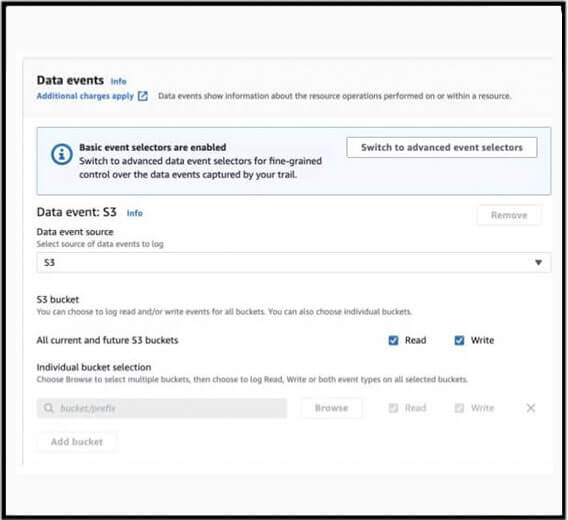
Afin d'obtenir une visibilité sur les événements affectant les objets S3, vous devez opter pour la collecte d'événements de données S3. La portée de ces événements peut être configurée pour inclure "Tous les buckets S3 actuels et futurs" ou des buckets individuels peuvent être énumérés. Ce paramètre de CloudTrail sert de mécanisme de filtrage pour intégrer des buckets spécifiques dans la journalisation du plan de données S3.
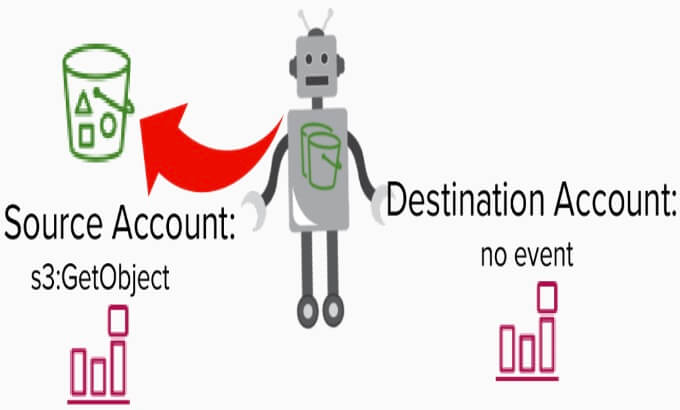
Lorsque des données sont copiées par le service de réplication S3, un événement GetObject se produit car le service saisit l'objet lors de la réplication. Cet événement est écrit dans le CloudTrail du compte source.
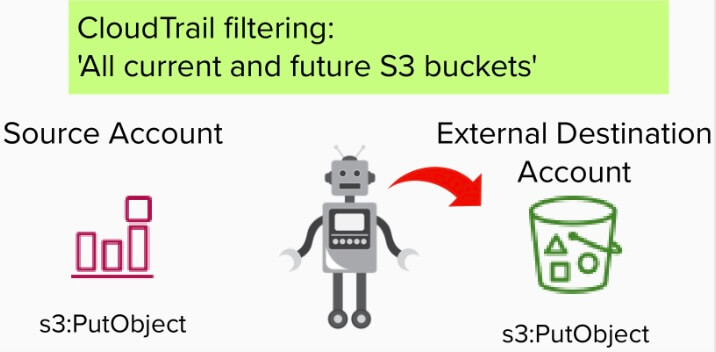
Après l'événement GetObject, l'événement PutObject, qui révèle le seau de destination, est enregistré à la fois dans le compte de destination externe et dans le compte source.
Quel est le comportement de la journalisation du plan de données S3 de CloudTrail si les journaux sont limités à des godets spécifiques ?
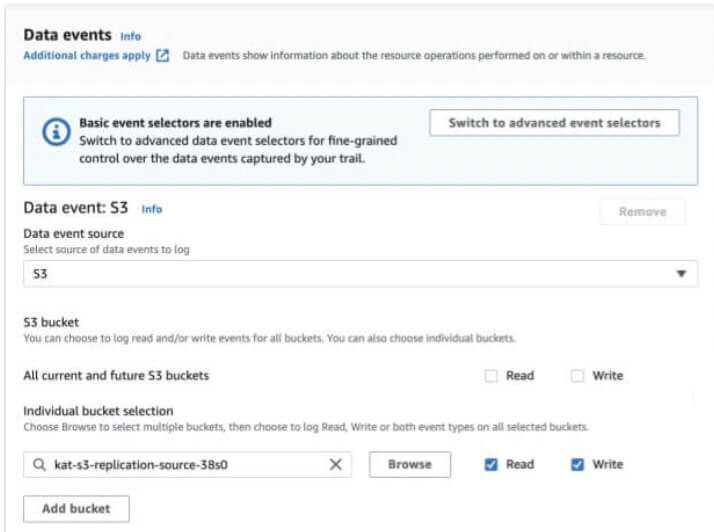
Pour contrôler les coûts, les organisations activeront souvent les journaux du plan de données S3 uniquement sur leurs buckets de grande valeur plutôt que de payer pour la journalisation sur "tous les buckets actuels et futurs". Comment cette configuration de journalisation modifie-t-elle la visibilité du service de réplication S3 ?
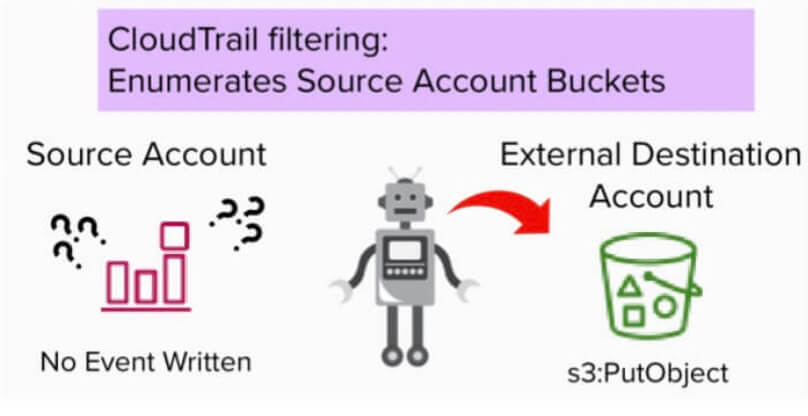
Après l'événement GetObject , un événement PutObject peut être enregistré dans le compte de destination conformément à la configuration CloudTrail du compte de destination. Il est à noter qu'aucun événement PutObject ne sera enregistré dans le compte source.

En pratique, cela signifie que lorsque les données sont copiées par le service de réplication, il n'y a pas d'enregistrement dans le CloudTrail du compte source révélant le seau de destination externe.

Lorsque CloudTrail est configuré pour capturer les événements du plan de données S3 à partir de godets spécifiques du compte source, il existe une lacune dans la journalisation, permettant la copie de données sans enregistrer l'événement du plan de données, PutObject, dans le compte source.
En l'absence de journaux de plans de données dont la portée inclut les journaux de tous les seaux actuels et futurs, un attaquant pourrait mettre à jour les règles de réplication pour répliquer les objets vers leur seau externe - et se détendre pendant que le service de réplication déplace silencieusement les données hors de l'entreprise.
Heureusement, les contrôles préventifs sont clairs.
Comme toujours, lors de la définition des politiques d'identité AWS IAM, ne laissez pas le champ de la ressource vide, ce qui permettrait aux autorisations de s'appliquer à n'importe quelle politique. Assurez-vous que le rôle IAM que le service de réplication assume énumère explicitement les buckets sur lesquels il est autorisé à opérer.
Quelles sont les conséquences pour les défenseurs de cloud ?
Les chasseurs de théat peuvent utiliser la mise à jour malveillante des règles de réplication comme un indice que l'exfiltration de données peut se produire silencieusement dans leur environnement.

Étant donné que l'abus de service est évitable avec le service de réplication S3 et que ce manque de visibilité est important pour les chasseurs de menaces et les défenseurs cloud du monde entier, il est important de savoir que le service de réplication S3 n'est pas un service de réplication, mais un service de réplication.

Pour comprendre l'importance de ces incohérences de journalisation, nous devons parler de la mission du défenseur dans une organisation. Les défenseurs de Cloud posent continuellement des questions sur l'environnement cloud à la recherche d'indicateurs de compromission. Leur travail consiste à détecter les cas où les choses dérapent, malgré tous les efforts déployés par les mesures préventives.

Le pain et le beurre d'un défenseur sont les journaux qu'il utilise pour élaborer des détections afin de fournir des signes d'alerte précoce indiquant que des données sortent du périmètre. Les journaux de plans de données à la disposition des défenseurs peuvent être limités à des ensembles connus et de grande valeur pour répondre à des préoccupations de coût et réduire le volume de journaux de plans de données qui peuvent être générés lors de la capture de tous les plans de données.

Si les données peuvent être copiées sans que le seau de destination soit enregistré, les défenseurs ne peuvent pas donner l'alerte ou rechercher l'exfiltration de données en recherchant les mauvais seaux dans les événements du plan de données tels que les événements CopyObject ou PutObject.

Les défenseurs doivent élargir les événements qu'ils surveillent pour y inclure la mise à jour des règles de réplication afin de s'assurer qu'ils surveillent de manière exhaustive le périmètre de leurs données.
Si un SOC n'est pas en mesure d'imposer la journalisation du plan de données S3 sur tous les buckets actuels et futurs, la surveillance et l'alerte sur l'événement PutBucketReplication est le seul endroit où un défenseur aura une visibilité sur les buckets de destination externes. Cet événement n'indique pas que des données ont été copiées, mais seulement que le service de réplication a une règle configurée pour copier des données.

Leçons tirées de l'utilisation abusive du service de réplication
Le service de réplication S3 peut aider les organisations à mieux résister aux ransomwares, mais il est important, lors de l'élaboration de notre modèle de menace, de créer des scénarios malveillants afin de nous aider à examiner cloud du point de vue d'un pirate informatique.
En raison du coût, une organisation typique peut hésiter à activer la journalisation du plan de données S3 sur tous les buckets d'un compte, préférant capturer sélectivement les logs uniquement sur les buckets de grande valeur. Comme nous l'avons vu, cette stratégie entraînera une lacune dans la visibilité de l'exfiltration S3 puisque l'événement PutObject ne sera pas écrit dans le compte source.
En août 2022, AWS avait refusé de résoudre le problème de journalisation avec le service de réplication S3. En discutant de ce problème avec AWS, les solutions ou "demandes de fonctionnalités" suivantes ont été proposées.
- Inclure le seau de destination dans l'événement GetObject
- Il est préférable de considérer les événements GetObject et PutObject comme des paires - l'écriture de ces deux événements dans le compte source est le résultat du filtre de portée du seau source plutôt que de considérer la portée du journal du plan de données du seau de destination.
Calendrier des rapports
21
[Vectra] : Envoi du rapport initial sur la vulnérabilité et accusé de réception le jour même.
21
[AWS] : A répondu en indiquant qu'il ne pense pas qu'il s'agisse d'une vulnérabilité :
"Nous ne pensons pas que le comportement que vous décrivez dans ce rapport pose un problème de sécurité, il s'agit plutôt d'un comportement attendu. Nous proposons un système d'alarme CloudWatch qui enregistre toutes les modifications apportées à la politique de réplication d'un bucket [1], ce qui permet de connaître la destination des données pour le modèle de menace décrit. Voir la section détaillant "S3BucketChangesAlarm".
21
[Vectra] : J'ai demandé la confirmation qu'AWS ne considère pas l'absence de journalisation comme une vulnérabilité. J'ai indiqué que je décrirai la réponse d'AWS à ce rapport comme "ne corrigera pas" dans toute divulgation publique.
21
[AWS] : AWS a demandé où je publierais la divulgation et s'ils pouvaient avoir une copie anticipée du texte.
21
[Vectra] : A reconnu qu'il pouvait recevoir une copie anticipée de toute divulgation publique.
22
[Vectra] : Renvoi du rapport de vulnérabilité original à un contact interne de l'équipe de sécurité d'AWS pour lui suggérer de faire une demande d'amélioration de la journalisation sur le service de réplication S3.
22
[AWS] : Reconnaît avoir déposé le ticket en interne.
22
[Vectra] : A publié une première recherche sur le sujet qui décrivait le problème de journalisation comme se produisant uniquement lorsque le contrôle du temps de réplication (RTC) était activé.
22
[Vectra] : Re-testé les trouvailles pour découvrir un manque de journalisation se produisant avec ou sans RTC activé.
7/26/22
[Vectra] : Résultats présentés à fwd:cloudSec
22
[Vectra et AWS] : Réunion pour discuter des résultats. Lors de cette réunion, il a été entendu que le filtre de cadrage du plan de données S3 de CloudTrail est le mécanisme qui contrôle si un événement PutObject est écrit ou non sur le compte source.
[1] https://docs.aws.amazon.com/awscloudtrail/latest/userguide/awscloudtrail-ug.pdf